论文阅读笔记:Controlling Vision-Language Models for Multi-Task Image Restoration

摘要
视觉语言模型,如CLIP,在零样本或无标签预测的各种下游任务中显示出巨大的影响。然而,当涉及到低级视觉,如图像复原时,由于损坏的输入,它们的性能急剧恶化。在本文中,我们提出了一种退化感知的视觉语言模型(DA-CLIP),以更好地将预训练的视觉语言模型迁移到低级视觉任务中,作为图像恢复的多任务框架。更具体地说,DA-CLIP训练一个额外的控制器,该控制器适应固定的CLIP图像编码器,以预测高质量的特征嵌入。通过将嵌入操作集成到一个基于交叉注意力的图像复原网络中,我们可以引导模型学习一个高保真的图像重建。控制器自身也会输出一个与输入的真实退化特征相匹配的退化特征,从而产生一个针对不同退化类型的自然分类器。此外,我们构建了一个带有合成字幕的混合退化数据集用于DA-CLIP训练。我们的方法在退化特定的和统一的图像复原任务上都取得了先进的性能,显示了使用大规模预训练的视觉语言模型来促进图像复原的一个很有前途的方向。
引言
研究背景和问题
现有大规模视觉语言模型(VLM)在图像恢复(IR)等底层视觉任务中表现有限,主要原因在于:
- 特征对齐不足:VLM未有效区分退化类型(如模糊、噪声)的细粒度差异,导致图像特征与退化文本描述不匹配。
- 数据局限性:VLM通常基于网络规模数据集训练,而IR模型依赖小规模、任务特定的数据集,缺乏图像-文本对支持。
传统IR方法仅关注逐像素生成,需针对不同退化类型重复训练模型;最近的工作集中在统一图像恢复上,在混合退化数据集上训练单个模型,并隐式地对恢复过程中的退化类型进行分类,但它们仍然局限于少数退化类型和与之相关的特定数据集。特别是,它们没有充分利用VLM的丰富知识。
解决方法
作者提出了退化感知CLIP(DA-CLIP),将CLIP模型与IR网络结合,形成多任务框架,适用于退化特定与统一IR任务: 1. 图像控制器(Image Controller): - 调整CLIP图像编码器,输出与纯净文本描述对齐的高质量(HQ)内容嵌入。 - 同时预测退化嵌入以匹配真实退化类型,解决退化输入与干净文本间的特征不匹配问题。 2. 知识融合:通过嵌入VLM的人类级知识,提升图像恢复性能并实现跨退化类型的统一恢复。
数据构建和训练
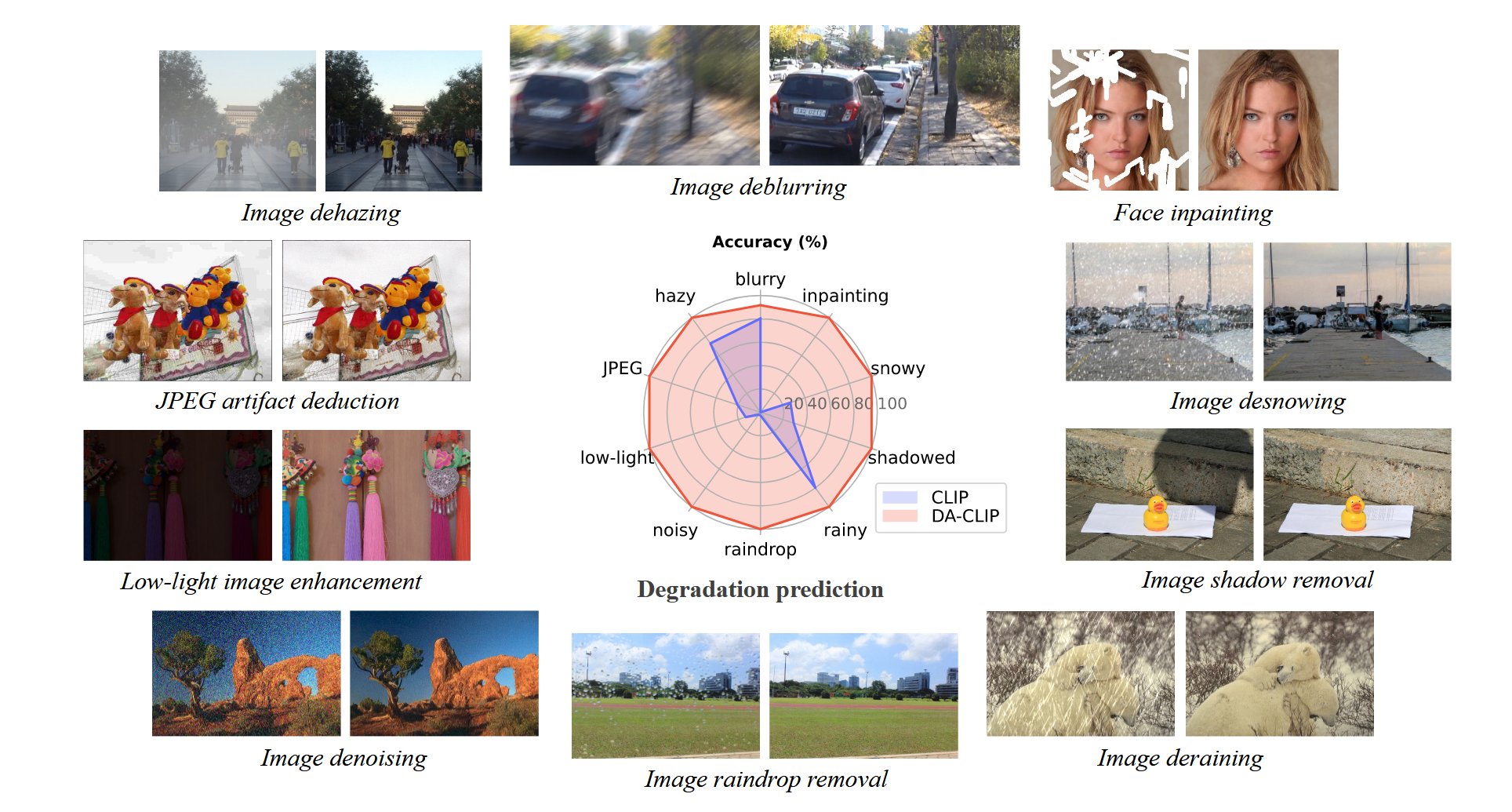
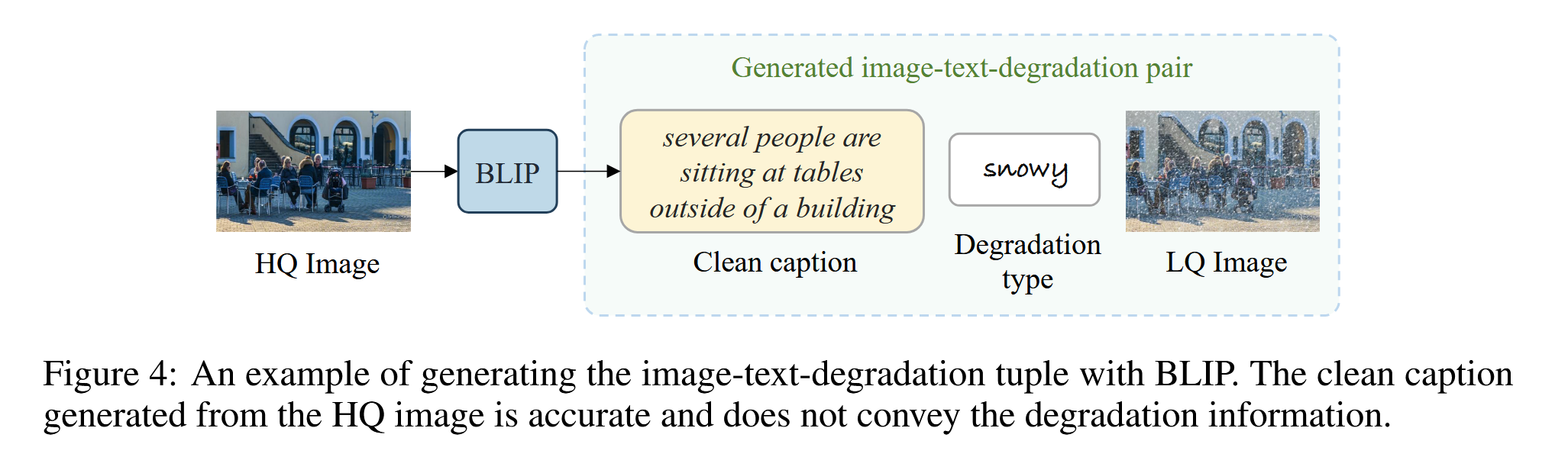
为了训练DA-CLIP从低质量(LQ)输入中学习高质量特征和退化类型,作者为十个不同的图像恢复任务构建了一个大型混合退化数据集。具体来说: - 使用BLIP为所有HQ图像生成合成字幕,然后将LQ图像与字幕和相应的退化类型匹配为图像-文本-退化的三元组数据。 - DA-CLIP可以准确地对十种不同的退化类型进行分类,并可以很容易地集成到现有的恢复模型中(即同时学习HQ特征和退化类型特征)
主要贡献
我们的主要贡献总结如下:
- 提出了DA-CLIP来利用大规模预训练的视觉语言模型作为图像恢复的通用框架。关键组件是图像控制器,它预测退化并适配冻结的CLIP图像编码器,以从损坏的输入中输出高质量的内容嵌入。
- 利用交叉注意力将内容嵌入融入复原网络,提高复原网络的性能。此外,我们引入了提示学习模块,以更好地利用退化上下文进行统一的图像复原。
- 构建了一个包含10种不同退化类型的高质量合成字幕的混合退化数据集。该数据集既可以用来训练DA-CLIP,也可以用来训练统一的图像复原模型。
- 将DA-CLIP应用到图像复原模型中,分别应用于特异性退化和统一的图像复原任务,验证了DA-CLIP的有效性。该方法在所有十种退化类型中都取得了极具竞争力的性能。
总结
DA-CLIP通过融合VLM的语义知识与退化感知机制,解决了IR任务中特征对齐与多退化统一恢复的难题,为通用图像恢复提供了新思路。
DA-CLIP
论文方法的核心是控制预训练的CLIP模型,以从损坏的图像中输出高质量的图像特征,同时预测退化类型。如图2所示,图像内容嵌入\(e_c^I\)与干净的标题嵌入\(e_c^T\)相匹配。此外,由控制器预测的图像退化嵌入\(e_d^I\)指定输入的损坏类型,即来自文本编码器的相应退化嵌入\(e_d^T\)。然后可以将这些特征集成到其他图像恢复模型中,以提高它们的性能。
原本的CLIP是清晰图像匹配本文,但是现在输入的是损坏图像,这就会导致潜在图像内容无法正确匹配GT文本,这里用Image Controller对CLIP的图像编码器微调,使之适应损坏图像。此外,CLIP的额外输入还有一个降质类型,这个是Image Controller来额外预测的。
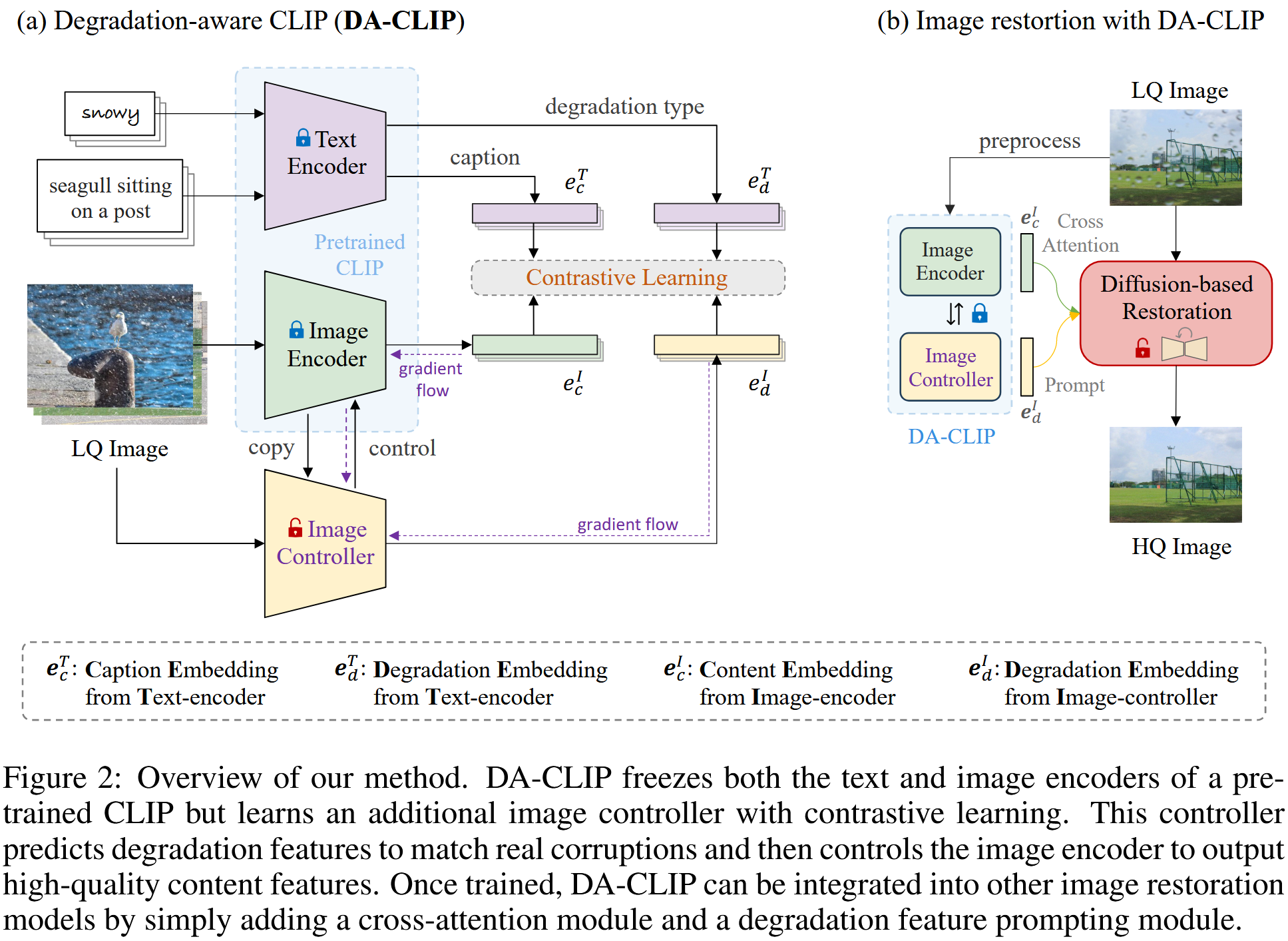
Image Controller
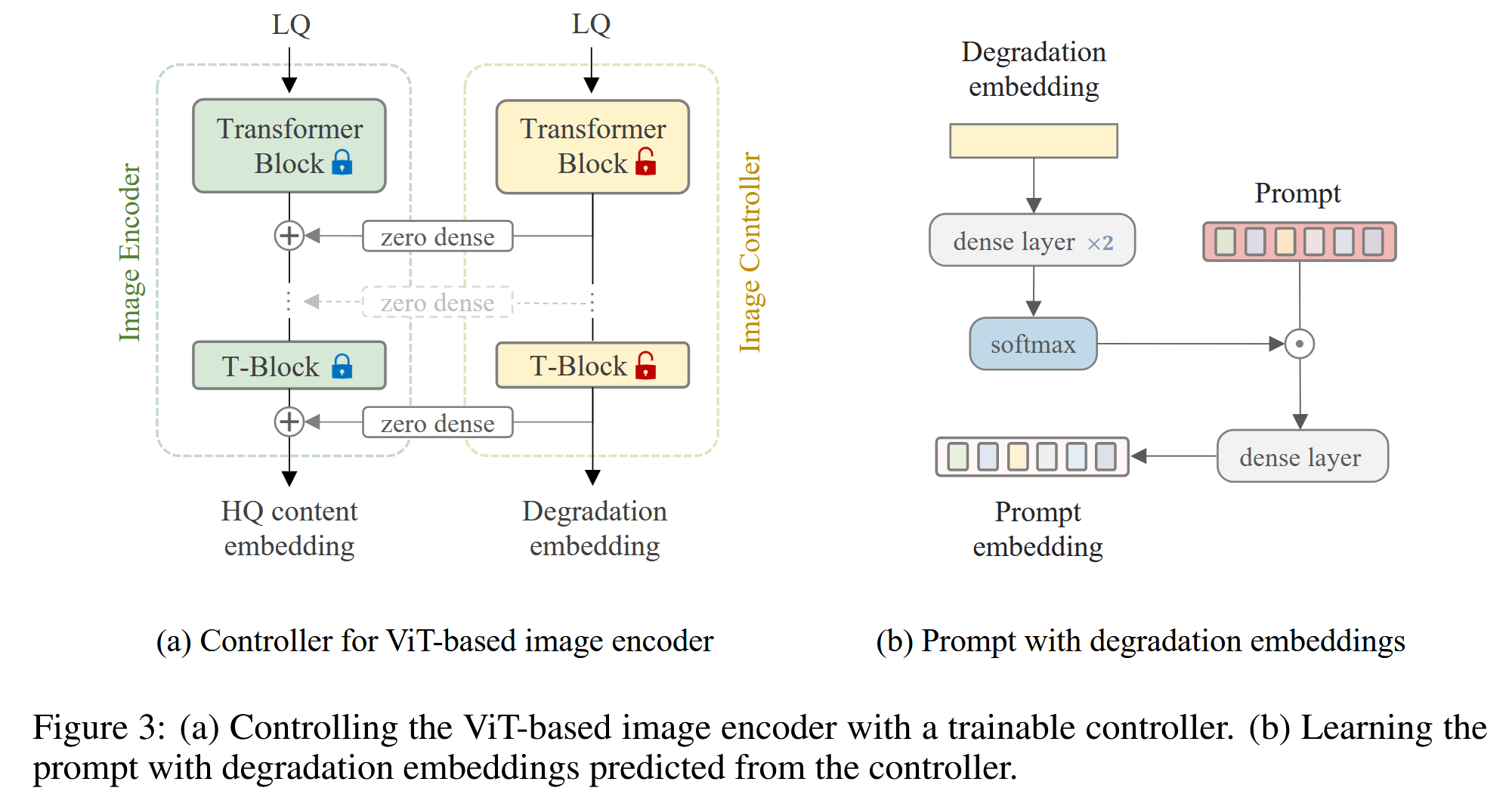
图像控制器是CLIP图像编码器的副本,但使用一些零初始化连接进行包装,以向编码器添加控制。它操纵所有编码器块的输出以控制图像编码器的预测。在本文中,使用ViT作为编码器和控制器的默认主干。
图3(a)说明了控制过程,其中控制器的输出由两部分组成: 1. 图像退化嵌入\(e_d^I\) 2. 隐藏控件\(h_c\)(包含来自transformer块的所有输出,这些输出随后被添加到相应的编码器块以控制它们的预测)
transformer块之间的连接是简单的密集神经网络,所有参数都初始化为零,这在训练过程中逐渐影响图像编码器。由于与VLM中使用的网络规模数据集相比,训练数据集很小,因此这种控制策略在保持原始图像编码器能力的同时减轻了过拟合。
冻结预训练的CLIP模型的所有权重,只微调图像控制器。 为了使退化嵌入空间具有判别性和良好的分离性,使用对比目标来学习嵌入匹配过程。设\(N\)表示训练批中成对嵌入(来自文本编码器和图像编码器/控制器)的数量。对比损失定义为:
\[ \mathcal{L} _{\mathrm{con}}\left( x,y \right) =-\frac{1}{N}\sum_{i=1}^N{\log \left( \frac{\exp \left( x_{i}^{T}y_i/\tau \right)}{\sum_{j=1}^N{\exp \left( x_{i}^{T}y_j/\tau \right)}} \right)}, \]
然后为了优化内容和降质嵌入,使用以下共同目标: \[ \mathcal{L} _c\left( \omega \right) =\mathcal{L} _{\mathrm{con}}\left( e_{c}^{I},e_{c}^{T};\omega \right) +\mathcal{L} _{\mathrm{con}}\left( e_{d}^{I},e_{d}^{T};\omega \right) , \]
这个损失函数的意思就是,先让CLIP的文本编码器对GT描述和降质类型编码得到\(e_c^T\)和\(e_d^T\),然后图2中的输入LQ得到输出\(e_c^I\)和\(e_d^I\)。他们做对比学习进行对齐,就可以实验LQ输入匹配HQ的captions和types的编码。
图像复原
使用IR-SDE作为图像恢复的基本框架。它采用了类似于DDPM的U-Net架构,但删除了所有自注意层。为了将纯净的内容嵌入注入扩散过程,作者引入了一种交叉注意力机制,从预先训练的VLM中学习语义指导。考虑到图像恢复任务中输入大小的变化以及将注意力应用于高分辨率特征的成本的增加,为了提高样本效率,只在U-Net的底部块中使用交叉注意力。
简单介绍下IR-SDE,它是与该博客介绍的文章相同的作者提出的一个专用于复原的扩散模型,对于不同任务都需要从头训练一个特定的模型。主要思想和这篇文章一模一样,但是IR-SDE更早点。 这篇论文的介绍博客在这里 IR-SDE工作概述

另一方面,预测的退化嵌入对于统一图像恢复是有用的,其中目标是用单个模型处理多种退化类型的低质量图像。如图1所示,DA-CLIP准确地对不同数据集和各种退化类型的退化进行了分类,这对于统一的图像恢复至关重要。此外,为了利用这些退化嵌入,作者将它们与即时学习模块相结合,以进一步改进结果,如图3(b)所示。这里的prompt应该就是content embedding。
通常,可以使用交叉注意力将内容嵌入集成到网络中,以提高它们在图像恢复任务上的性能。相比之下,结合退化嵌入的提示模块则专门针对统一图像复原背景下的退化类型分类进行改进。
数据构成
使用BLIP通过高质量的图像,生成准确的、干净的文本,并与对应的退化图像、退化类型进行组合。

实验
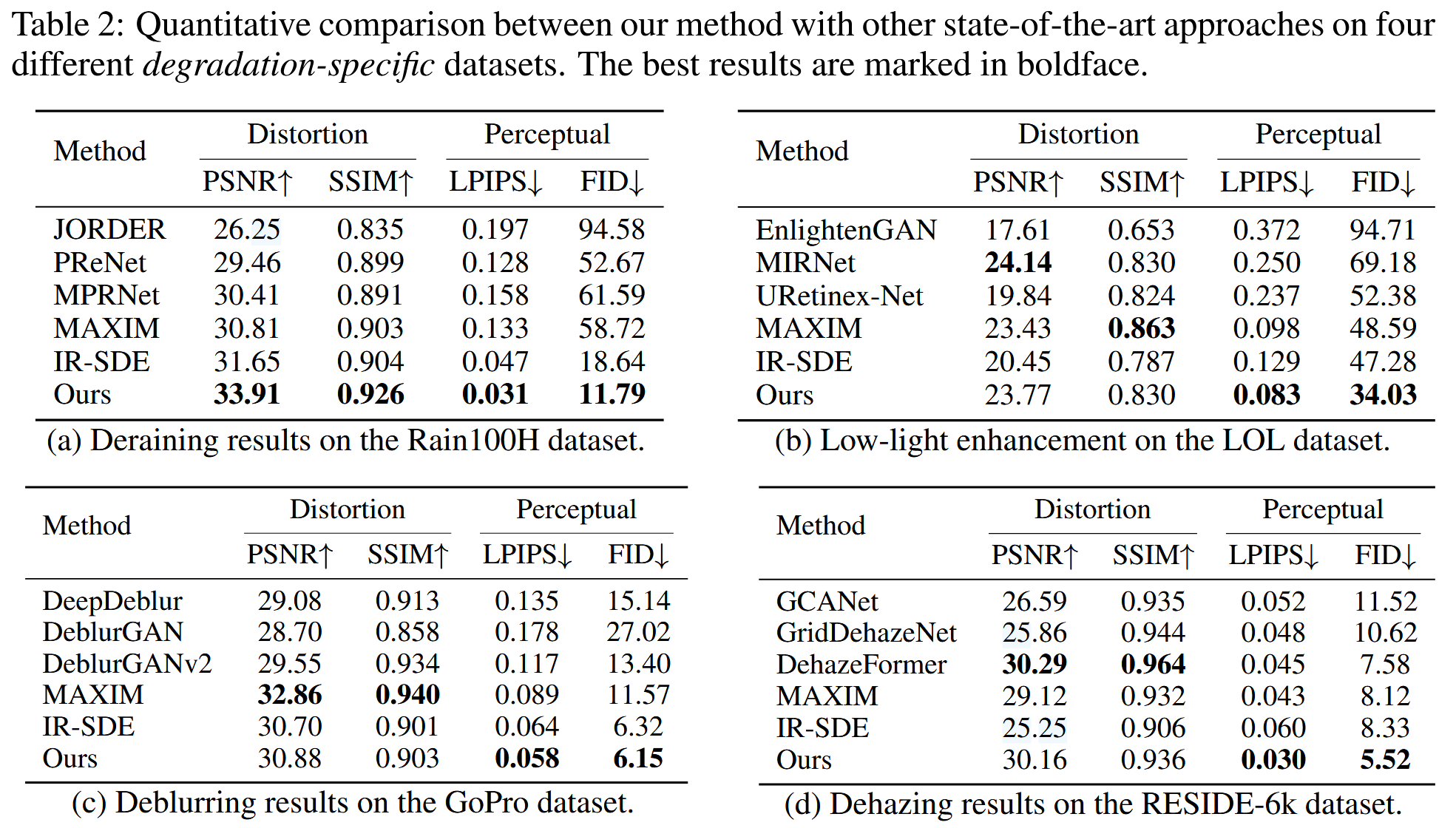
本文提出的方法与现有方法在四个特定退化类型的数据集上进行图像修复的的定量比较与可视化呈现:

本文方法与现有方法进行统一的图像复原任务在若干指标上的对比。每个雷达图报告了一个特定指标的十种不同退化类型的结果。

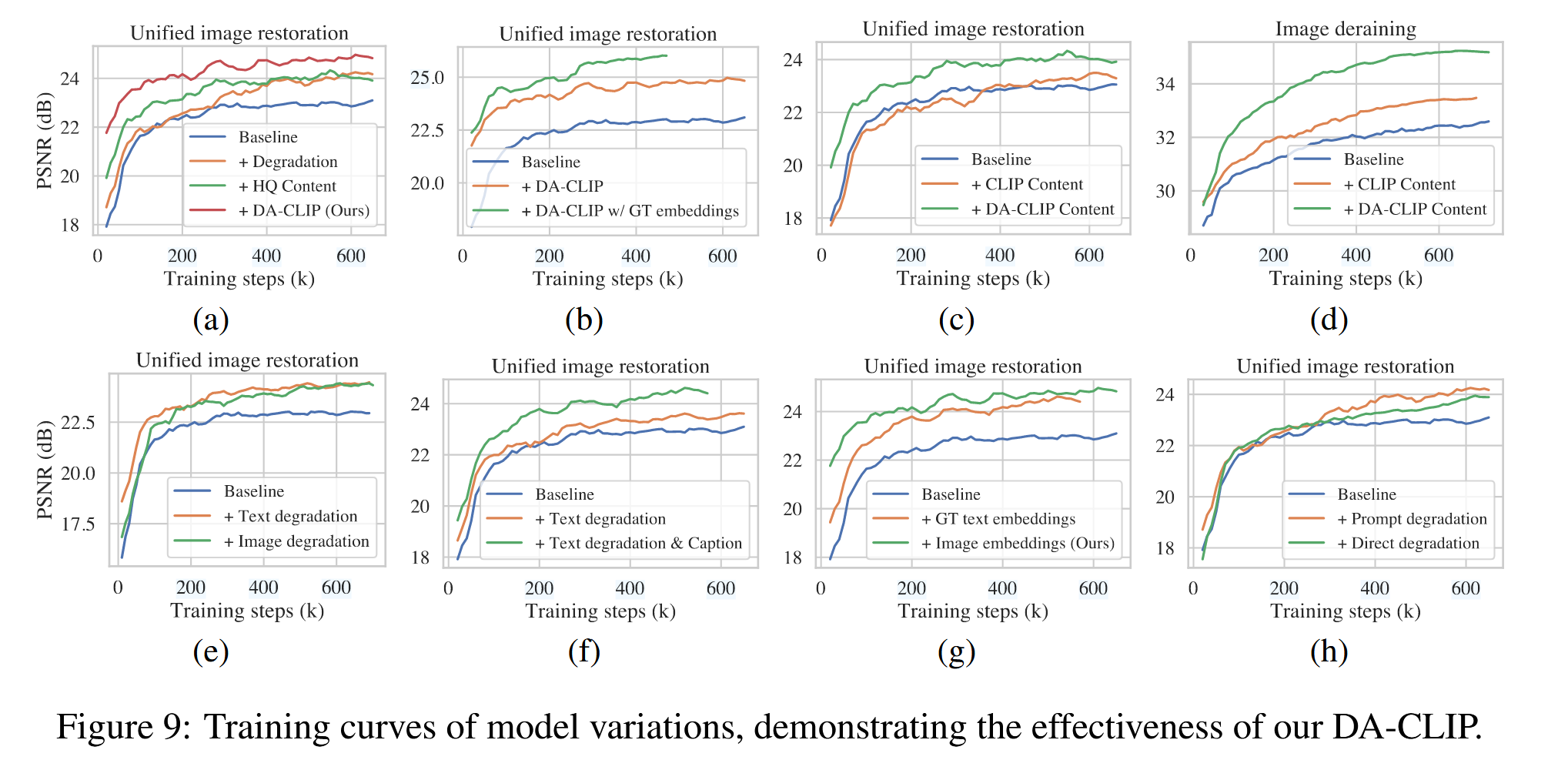
训练曲线证明DA-CLIP的有效性:
指标介绍
峰值信噪比(dB)。其中(L)表示图像数据类型最大动态范围([0,255]),(MSE)表示预测数据和原始数据的均方误差。PSNR越大说明评估结果越好。
[ \[\begin{aligned} PSNR&=\displaystyle{10\log _{10}\frac{L^2}{MSE}} \\ MSE&=\displaystyle{\frac{1}{mn}\sum_0^{m-1}{\sum_0^{n-1}{\left( f\left(i,j \right) -g\left( i,j \right) \right) ^2}}} \end{aligned}\] ]
PSNR在计算每个位置上的像素差异时,其结果仅与当前位置的两个像素值有关,与其它任何位置上的像素无关,忽略了图像内容所包含的一些视觉特征,特别是图像的局部结构信息。
SSIM计算两张图像在每个位置上的差异时,不是在该位置上从两张图中各取一个像素,而是各取了一个区域的像素。SSIM综合考虑了图像的亮度、对比度和结构,取值在([0,1])之间,越大说明结果越好。
[ SSIM( x,y ) = ]
(_x,_y)分别是图像(x,y)的均值,(_x^2,y^2)是方差,({xy})是协方差。(C_1=(k_1L)2,C_2=(k_2L)2)是稳定除法运算的小常数,(L)是像素值动态范围。默认取(k_1=0.01,l_2=0.03)。
通过训练一个神经网络学习图像块之间的差异,通常使用预训练的CNN作为特征提取器,然后训练一个额外的层预测图像对的相似性。取值范围([0,1]),取值越小越好。
用于评估生成图像和真实图像在特征空间中的分布差异,量化二者的距离。取值越小表示生成图像与真实图像越相似。
首先用Inception网络将图像映射到高维特征向量,计算这两个特征向量的均值向量和协方差矩阵,最后综合计算距离:
[ d^2=| _1-2 | {2}^{2}+( _1+_2-2( _1_2 ) ^{} ) ]
总结
本文提出DA-CLIP框架,利用大规模预训练视觉语言模型(VLM)构建通用图像恢复系统:
- 核心机制:
- 退化嵌入预测:通过控制器从低质(LQ)图像中精准提取退化特征。
- 内容嵌入对齐:控制CLIP图像编码器输出与干净内容对齐的高质量(HQ)特征。
- 训练数据:基于高质量图像生成合成文本描述,构建混合退化数据集。
- 下游应用:通过提示学习模块和交叉注意力机制,将DA-CLIP嵌入现有恢复模型。
在退化特定与统一恢复任务中,DA-CLIP显著提升多种退化类型的恢复性能。但当前数据集难以处理同一场景的混合退化问题。未来计划开发更鲁棒的模型,适配真实拍摄场景,并实现多退化类型的完全恢复。
- Title: 论文阅读笔记:Controlling Vision-Language Models for Multi-Task Image Restoration
- Author: Jachin Zhang
- Created at : 2025-02-05 20:23:50
- Updated at : 2025-03-04 21:18:48
- Link: https://jachinzhang1.github.io/2025/02/05/luoControllingVisionLanguageModels2024/
- License: This work is licensed under CC BY-NC-SA 4.0.