注意力机制解析

背景
注意力机制早在2014年便被首次用于计算机视觉领域,试图理解神经网络进行预测时正在观察的位置。2015年注意力机制开始用于NLP领域,后于2017年被加入Transformer网络中用于语言建模。Transformers解决了RNN存在的长程依赖、梯度消失和梯度爆炸、所需训练开销和无法并行计算等问题,取代了RNN在NLP领域的统治地位,成为该领域最受欢迎的技术。
词嵌入 (embedding)
对于自然语言文本,计算机难以直接使用,因此在NLP中第一步都是将自然语言的单词转化为等长的向量,这个过程叫做嵌入。向量的每个维度都有其潜在的含义,只不过在具体实践中难以对每个维度的含义做具体解释。
词嵌入并无普遍标准,同一个词的嵌入也会因为任务、神经网络、训练阶段的不同而不同。初始嵌入为随机值,在训练期间会不断调整从而最小化神经网络的误差。
举个例子,我们要将这句话输进计算机做处理:
句子被输入计算机时,程序将该字符串分为若干个token \(t\),每个token生成一个词嵌入\(a\)。但此时这些词嵌入不包含上下文信息,即对程序来说,这些词嵌入组合相当于一个无序地装着多个单词的词袋,包含的信息十分有限。
而当我们分析句中单词的语义时会发现单词间的关联程度并不和它们之间的距离直接相关,例如will和tomorrow的关联程度明显比其与come的关联程度更高。因此词语之间的关联程度需要根据上下文的语境决定。接下来我们试图调整tokens的词嵌入,使其包含上下文信息。
缩放点积注意力的推导
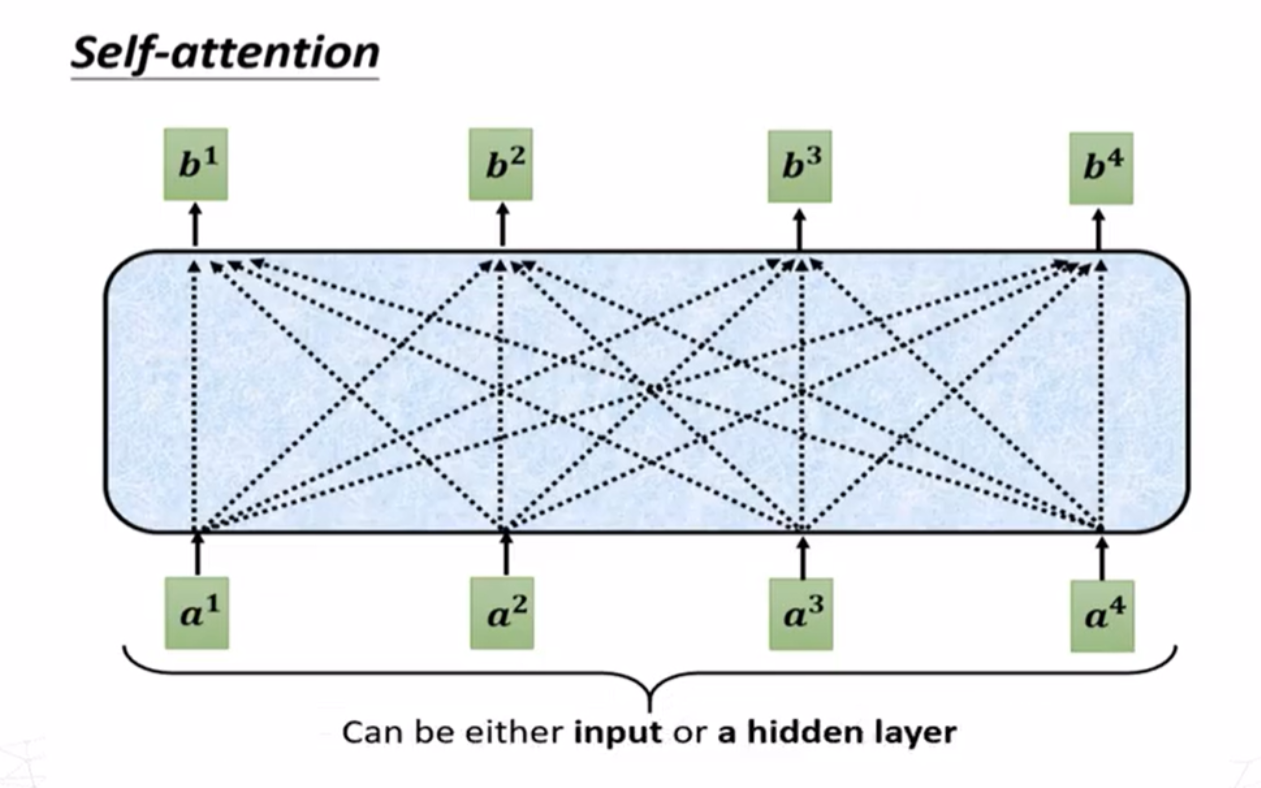
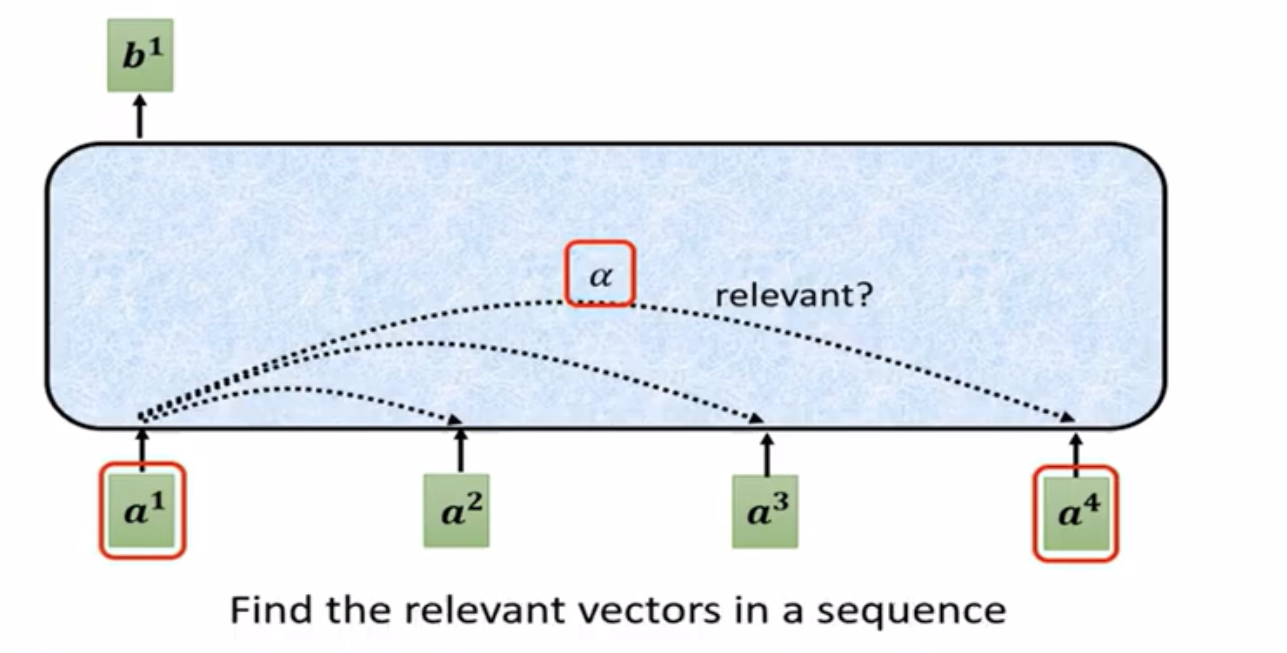
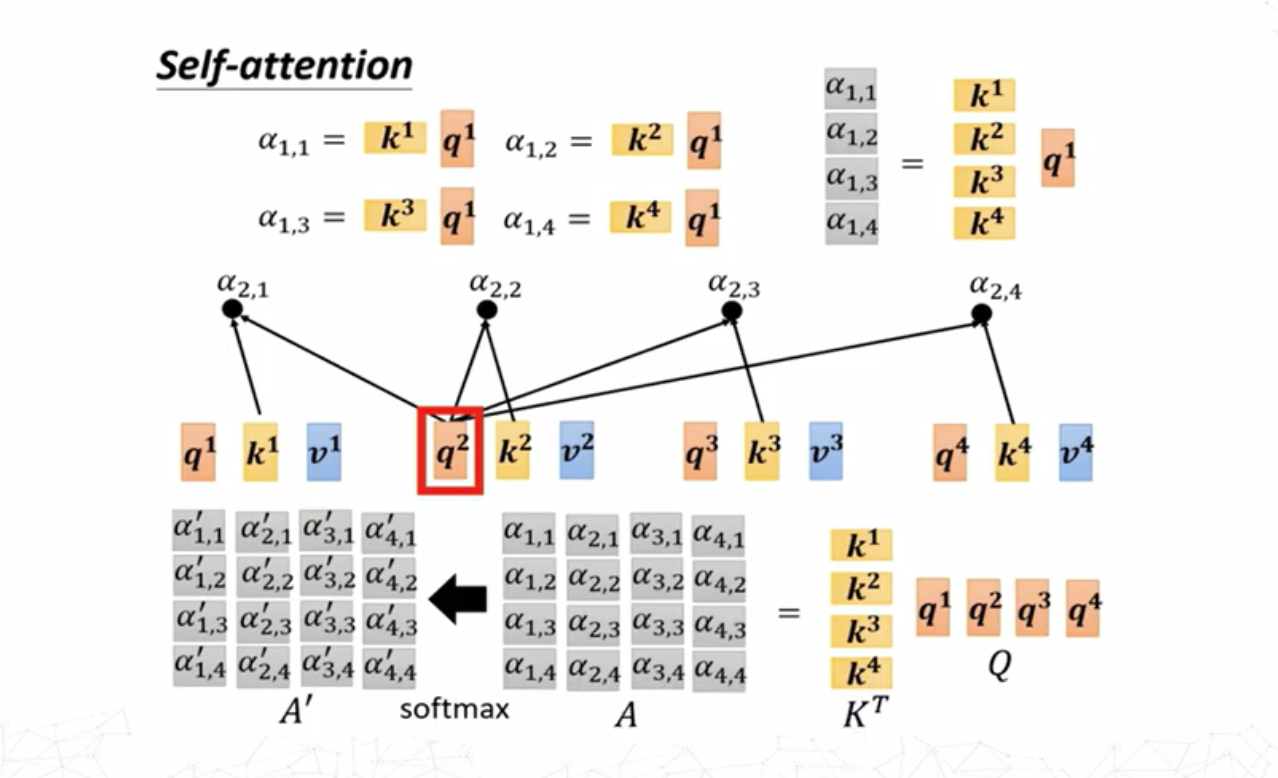
如图,\(a^i\)是不含上下文信息的词嵌入(这里以NLP的过程为例,事实上注意力机制还可以用于图像处理等,\(a^i\)可为初始输入或来自某个模型的输出),输出的结果\(b^i\)与所有词嵌入都有关。当我们了解\(b^1\)向量如何产生之后,其余向量的产生过程都可以很容易得到。产生\(b^1\)向量的首要步骤是找到\(a^1\)与其他向量的关联程度(也称注意力分数)。
对于求\(a^i,a^j\)之间的注意力分数\(\alpha_{i,j}\),最常用的方法是求出\(a^i\)的查询(query)向量 \[ q^i=W^qa^i \] 求出\(a^j\)的键值(key)向量 \[ k^j=W^ka^j \] 则注意力分数为查询向量和键值向量的点积 \[ \alpha_{i,j}=q^i\cdot k^j \]
这里求\(a^1\)与其他嵌入向量的关联度,求出其查询向量\(q^1\)之后与所有嵌入向量的键值向量\(k^i(i=1,2,3,4)\)做点积,最后对求出的关联度向量组作softmax归一化。
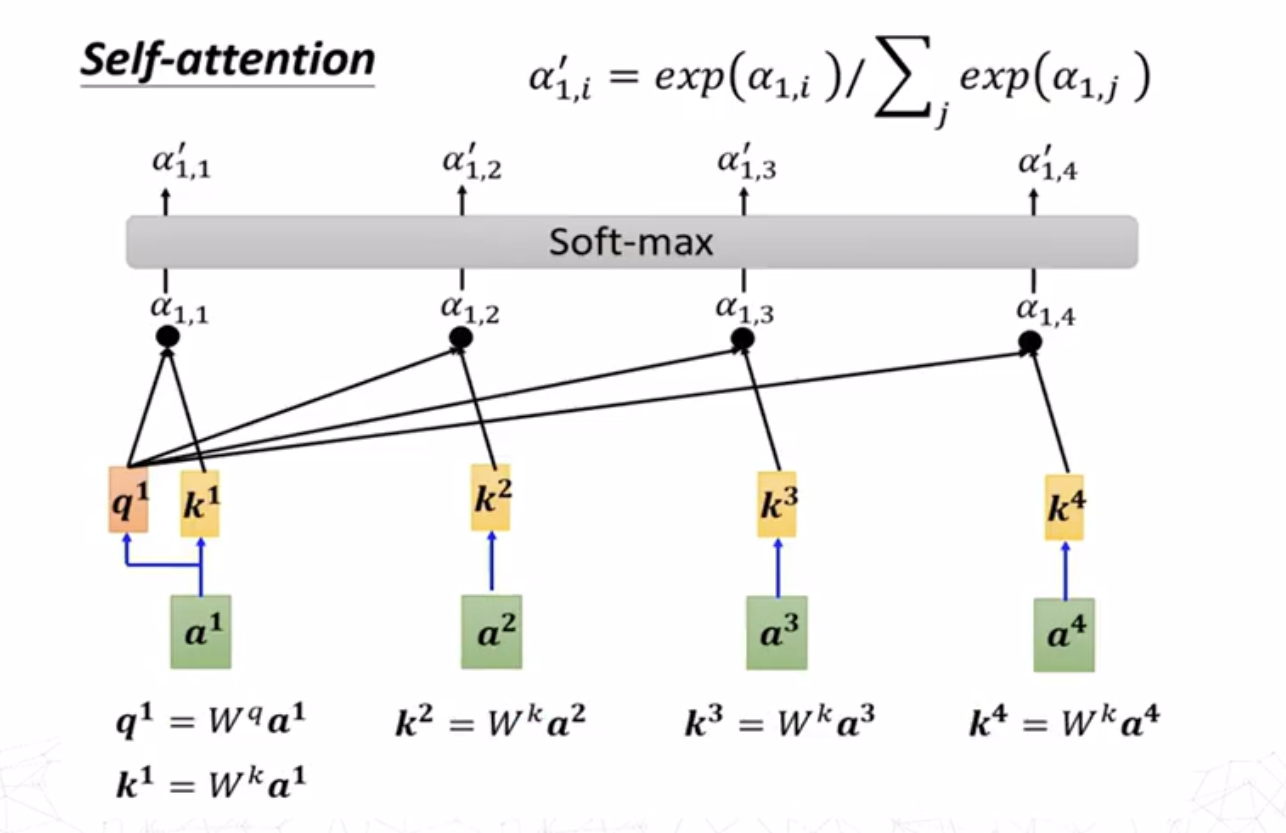
这个步骤可以简单理解为:在搜索引擎中输入的内容为\(q\),搜索到的结果展示了各种信息的键值\(k\),可以通过键值得到信息的内容(值,value)\(v\)本身。而关联度\(\alpha\)展示了这些信息与我们输入的内容的相关性有多大,这个值越大说明这个键值对应的内容和我输入的查询内容相关程度越高。
该步骤的激活函数并非必须为softmax,使用其他激活函数(如RELU,GELU等)也可,并且可能达到更好的效果。
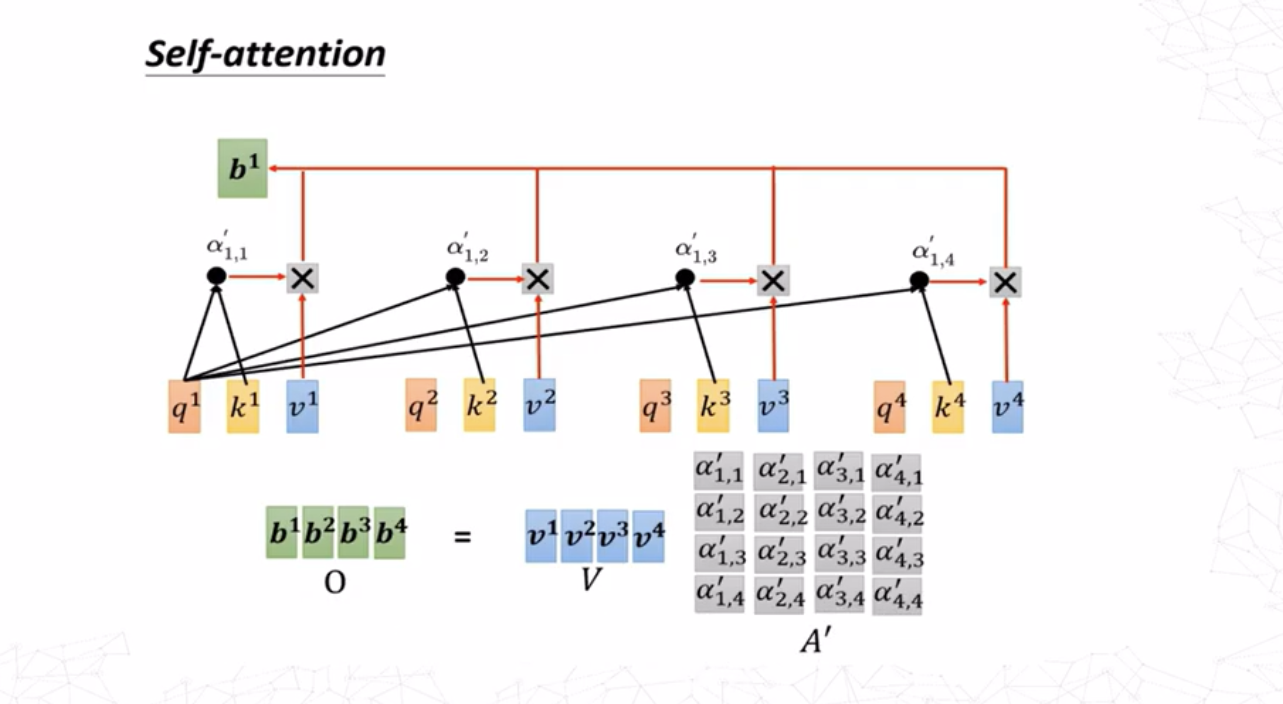
得到\(a^1\)与自身及其他几个嵌入向量的注意力分数之后,将这些分数与其对应向量的值向量相乘然后求和,即可得到添加了上下文信息的嵌入\(b^1\)。值向量可通过下式求得: \[ v^i=W^va^i \]
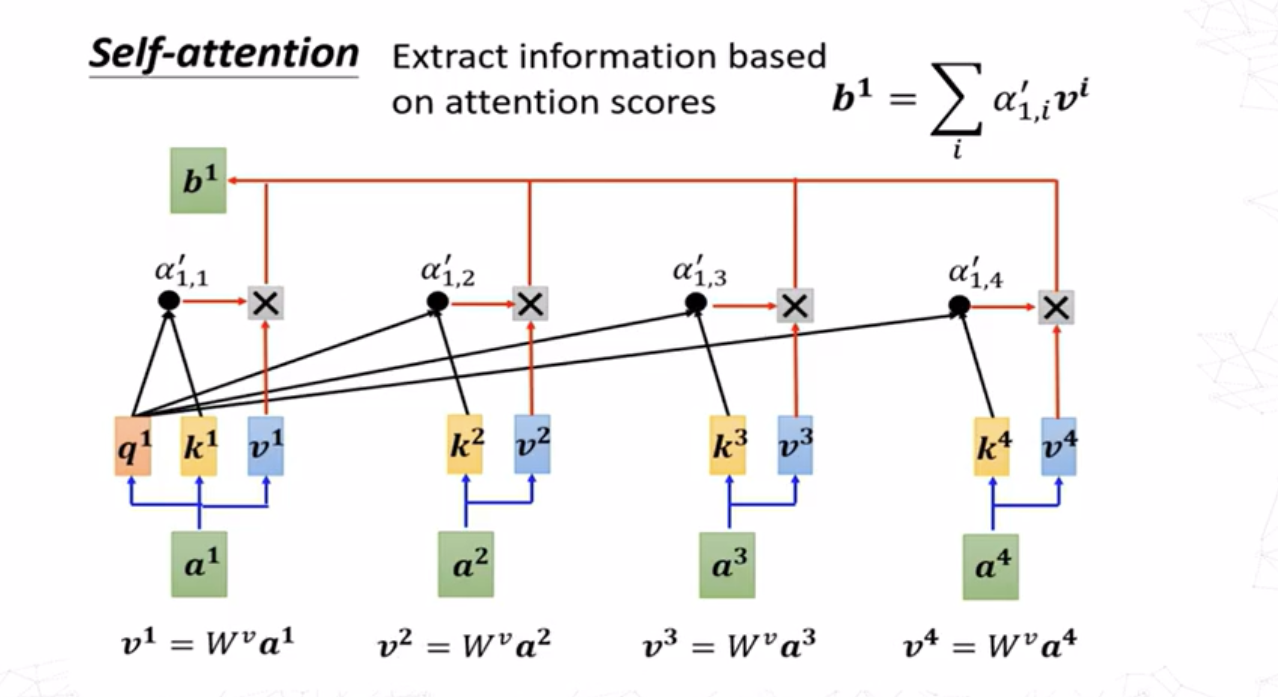
其余\(b\)向量的产生过程同理。值得注意的是,这个过程并不需要依序产生,所有\(b\)向量可以通过一组矩阵运算同时产生。
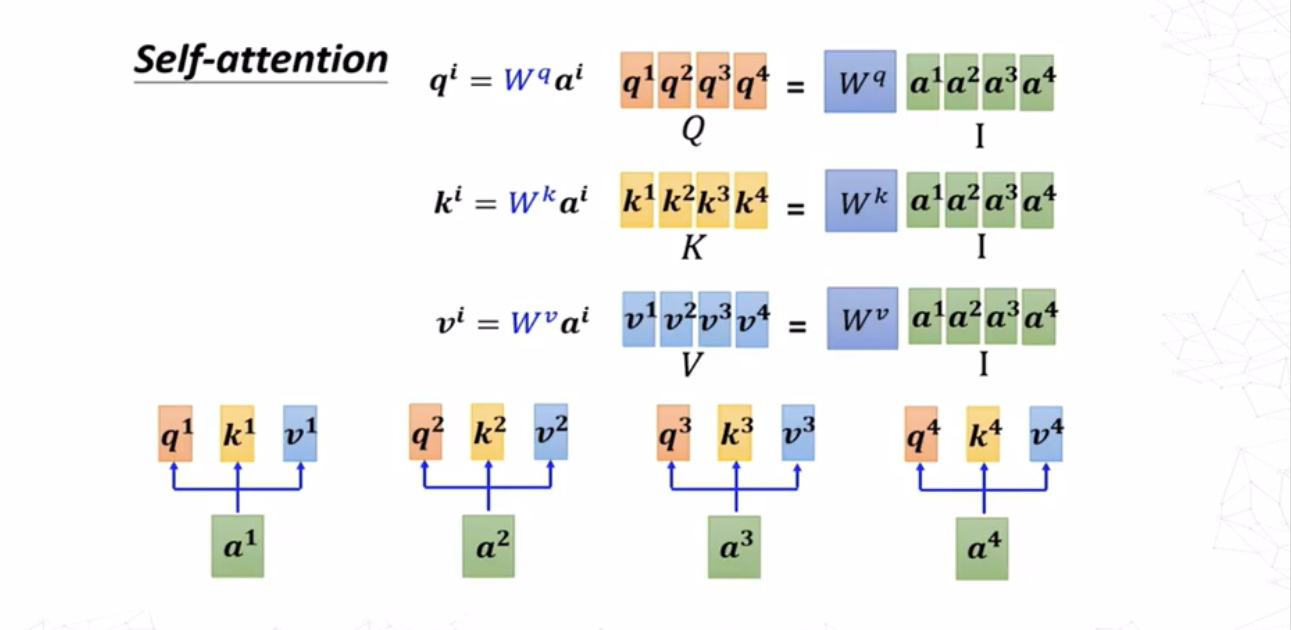
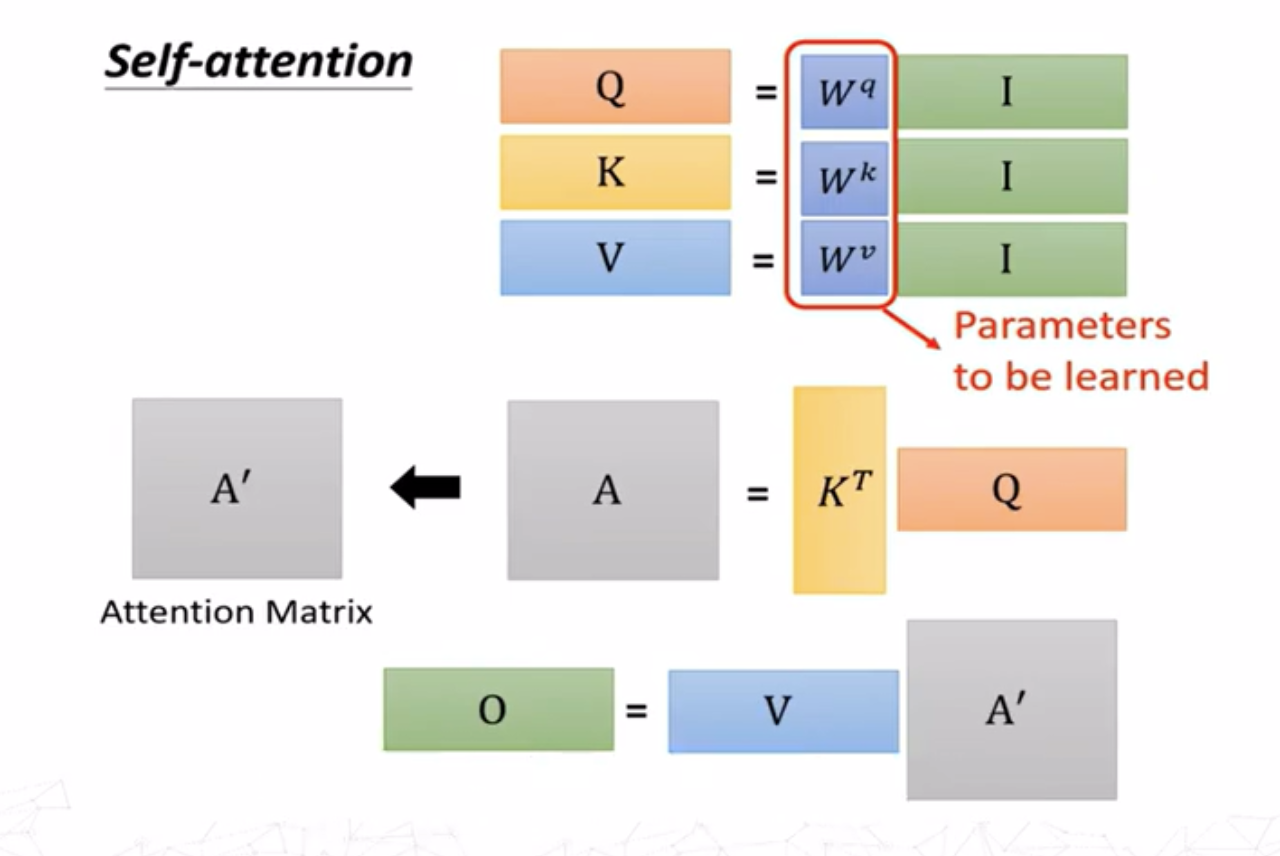
使用向量形式可以非常简洁地表述上述过程。假设: - 查询矩阵\(Q\in\mathbb{R}^{m\times d_k}\)(\(m\)表示查询的个数,\(d_k\)是查询向量的维度) - 键矩阵\(K\in\mathbb{R}^{n\times d_k}\)(\(n\)表示键的个数) - 值矩阵\(V\in\mathbb{R}^{n\times d_v}\)
每个查询\(q^i\)和每个键\(k^j\)之间的相似度用点积计算(如式\((3)\)),则所有查询和所有键的点积可以用矩阵表示: \[ A=QK^T \]
其中\(A\in\mathbb{R}^{m\times n}\)是所有查询和所有键的相似度矩阵。接着采用softmax对\(A\)进行归一化处理(对矩阵的每一行进行归一化): \[ A^\prime = \mathrm{softmax}(A) \]
最终注意力的输出值是值\(V\)的加权求和: \[ o_i = \sum_{j=1}^n{\alpha^\prime_{ij}v_j} \]
即 \[ O=AV \] 其中\(O\in\mathbb{R}^{m\times d_v}\)是最终的注意力输出矩阵。
值得注意的是,作者在原论文中提出了缩放因子: \[ A=\frac{QK^T}{\sqrt{d_k}} \]
其原因是:点积值的大小随着\(d_k\)增大而增大。如果\(d_k\)很大,\(QK^T\)的数值会很大,导致Softmax计算时指数项变大,使得梯度消失或过于集中于某些键值,确保注意力分布合理。
最终我们得到了完整的注意力机制公式: \[ \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\Big(\frac{QK^T}{\sqrt{d}}\Big)V \]
整个过程只有矩阵\(W^Q,W^K,W^V\)是需要训练的。
在机器翻译或文本生成的任务中,通常需要预测下一个单词出现的概率,这类任务要求注意力只能放在下一个词,不能放在更往后的词上。简而言之,注意力矩阵不能有非平凡的超对角线分量。这时我们可以通过添加掩码矩阵\(M\)来修正注意力,消除神经网络对未来的了解。即 \[ \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\Big(\frac{QK^T}{\sqrt{d}}+M\Big)V \]
其中, \[ \begin{aligned} M&=\left( m_{i,j} \right) _{i,j=0}^{n}\\ m_{i,j}&=\begin{cases} 0& i\ge j\\ -\infty& i<j\\ \end{cases}\\ \end{aligned} \]
利用神经网络结构表示注意力机制如下图所示:
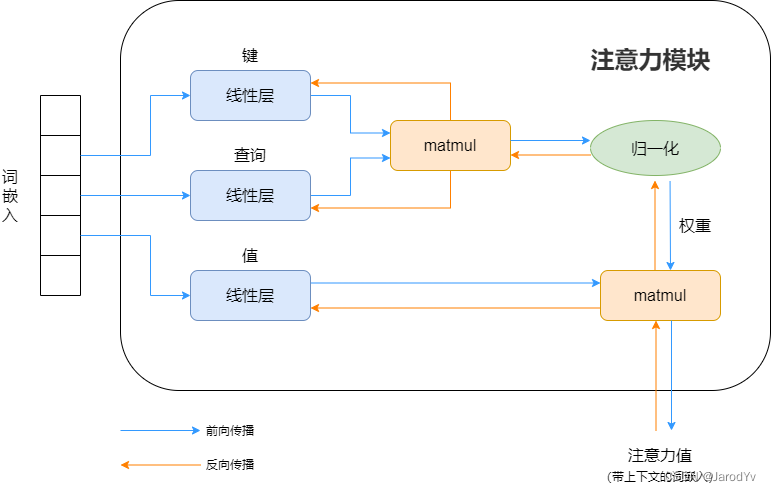
如何更好地理解注意力机制中的Q,K,V?
多头注意力机制
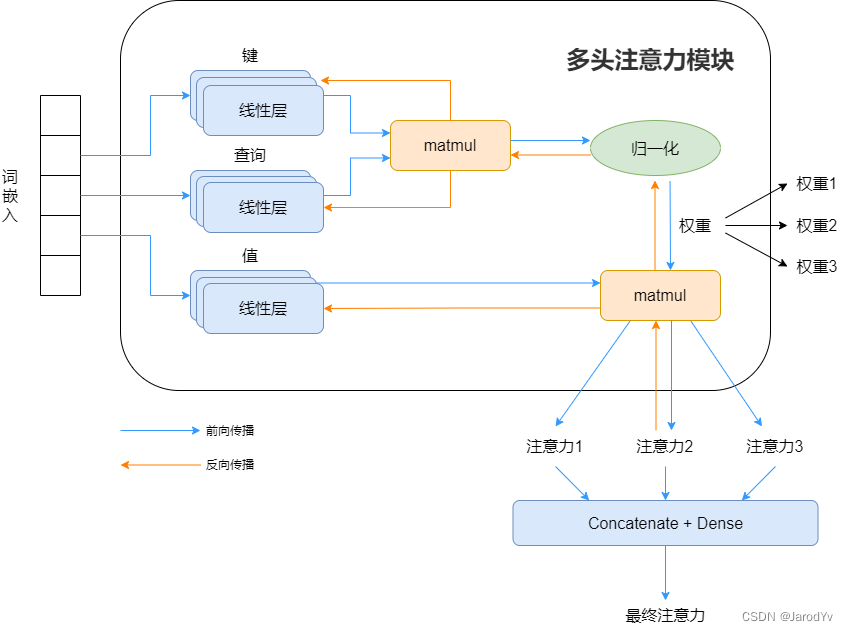
有时,只用一个注意力头可能无法很好捕捉多个词在语境上复杂的关联。因此,可以添加更多线性层作为键、查询和值。这些线性层在每轮并行训练,彼此权重独立,每层都各提供一个输出,从而各算出独立的权重。每一层被称为一个“头”。可以有任意数量\(h\)个线性层,提供\(h\)个注意力输出,然后将它们连接在一起。
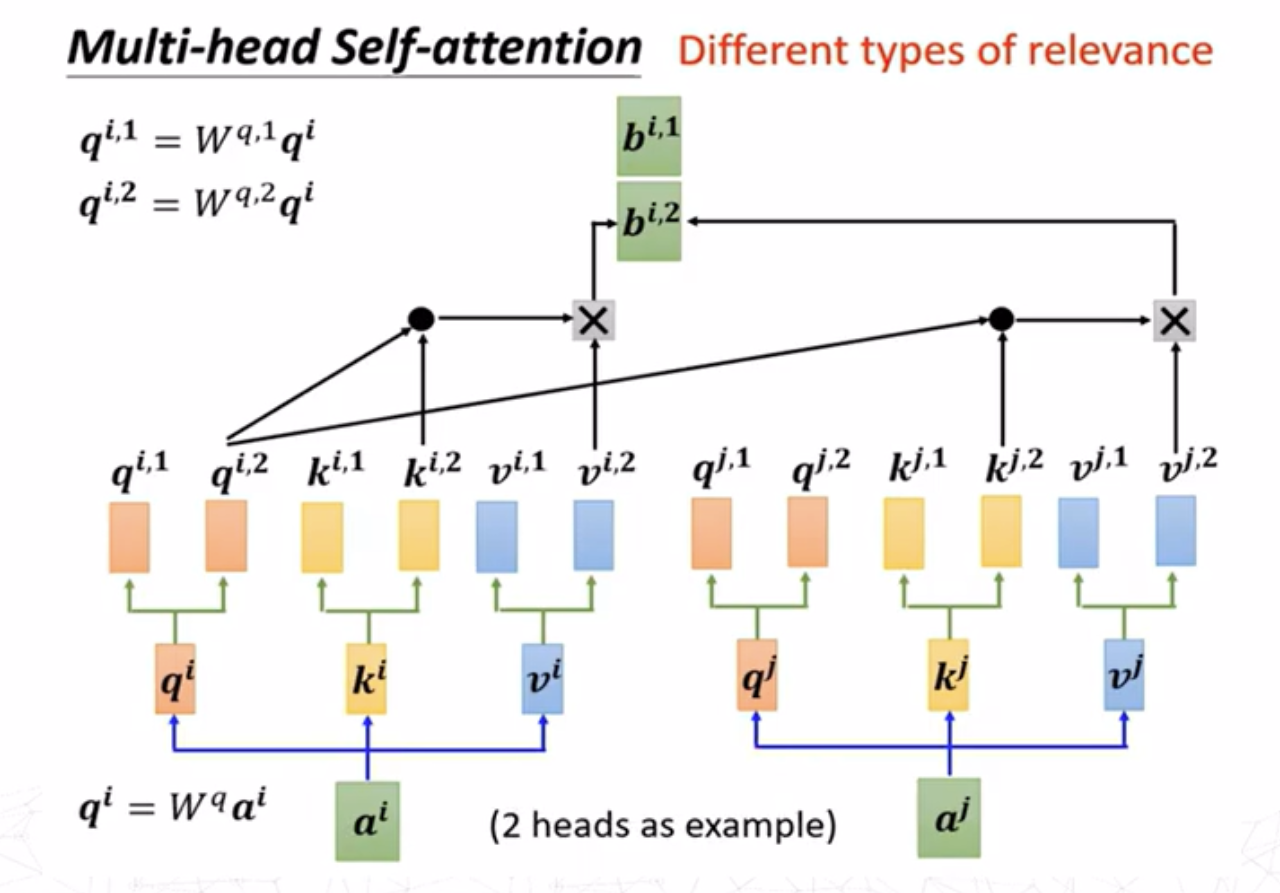
仿照上述的向量表示方法,多头注意力可以表示为 \[ \begin{aligned}\mathrm{head}_i&=\text{Attention}(QW_i^Q,KW_i^K,VW_i^V)\\ \text{MultiHead}&=\text{Concat}(\text{head}_1,\text{head}_2,\ldots,\text{head}_k)W^O\end{aligned} \]
其中\(QW_i^Q,KW_i^K,VW_i^V\)是不同头的参数矩阵。通过多个头学习不同的注意力模式,最终拼接后投影到输出空间。多头注意力能够提高模型的表达能力,并增强不同语义层次的表示。
缩放点积注意力的Pytorch实现
使用类ScaledDotProductAttention实现该注意力机制的模型:
1 | import torch |
接下来设置参数并尝试运行:
1 | batch_size, n_heads, seq_len, d_k, d_v = 1, 1, 5, 6, 3 |
对于其中各个参数和输出结果含义的解释: -
batch_size可理解为句子的数量(一次处理多少个句子) -
n_heads代表注意力头的数量 -
seq_len代表一个句子中包含多少个词元(tokens) -
d_k设置了query和key的维度 -
d_v设置了value的维度 -
output表示在输入的序列中,每个词元的value根据其他词元的相关性加权之后的结果,作为每个位置的最终表示
-
attn_weights是注意力分配给每个位置的权重,决定了查询i在计算输出时,从键j的值V[j]获取信息的程度
输出结果:
1 | torch.Size([1, 1, 5, 3]) |
- Title: 注意力机制解析
- Author: Jachin Zhang
- Created at : 2025-02-19 16:14:33
- Updated at : 2025-03-04 21:18:48
- Link: https://jachinzhang1.github.io/2025/02/19/AttentionAnalysis/
- License: This work is licensed under CC BY-NC-SA 4.0.