引言
图像分类任务是计算机视觉的核心问题之一,早在上世纪六十年代就已经开始发展。在深度学习技术出现之前,图像分类主要依赖人工设计特征,然后使用传统机器学习方法进行分类(如使用边缘检测等方法提取特征,然后使用SVM、KNN等分类器进行分类)。尽管这些方法在小规模数据集上取得了一定的成功,但它们的泛化能力很弱。并且特征提取需要大量专业领域知识,成本较高且不方便实行。
上世纪九十年代,神经网络开始进入研究者们的视野。但由于其计算资源消耗较大且模型可解释性弱,训练非常困难。1998年,由卷积层、池化层和全连接层组成的卷积神经网络(LeNet-5)出现,并在MNIST数据集上获得巨大的成功。
本文我们使用包含注意力层的卷积神经网络实现对CIFAR-10数据集的图像分类任务。
CIFAR-10数据集共包含60,000张图片,每张图片是32*32的RGB图像。整个数据集分为包含50,000个样本的训练集和10,000个样本的测试集。每个样本对应一个标签,用于描述该图片包含的物体。
另外,还有一个与之非常类似的数据集CIFAR-100,共有100个类,每个类包含600个样本,其中500个样本作为训练图像,100个样本作为测试图像。100个子类被分为20个大类,每个图像有一个“fine”标签(所属的子类)和一个“coarse”标签(所属的大类)。
下面使用Pytorch对该任务进行代码实现。
代码实现
配置文件
对于一个项目来说,我们要力求做到一套代码可以适应不同的参数,即当我们希望修改参数时,不应该对代码本身做出修改。而所用到的参数就可以放在配置文件中,供程序直接从中调用。
常用的方式主要有两种:
使用argparse库设定不同形参,在外部的sh脚本文件编写好确定了参数的命令,再运行该脚本文件。
使用yaml/yml文件存储参数,程序使用pyyaml库进行调用。
这里我们使用第2种方式。
在工作区创建options.yml文件,写入以下内容:
1 2 3 4 5 6 7 8 train: data_root: './data' n_epochs: 100 batch_size: 64 lr: 0.001 resume: false pretrained_path: ~ save_dir: './saved_model'
正常情况下,模型的训练与测试过程可以用下面这个流程图表示:
flowchart LR
subgraph ds [Dataset]
E[trainset]
F[valset]
G[testset]
end
A[Training] --> B[Validating]
B --> C{epoch <= MAX_EPOCHS?}
C -->|Yes| A
C -->|No| D[Testing]
E --> A
F --> B
G --> D
在整个模型的训练(Training+Validating)过程中是不能有测试数据集的出现的。打个比方,模型是一位高中生,训练集是平时的作业,验证集是平时的模拟卷,测试集就是最终的高考卷。
数据集下载和数据处理
新建文件dataset.py,写入以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import torchvisionfrom torchvision.transforms import transformsfrom torch.utils.data import DataLoaderimport yamlwith open ('./options.yml' , 'r' ) as f: opt = yaml.safe_load(f) transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5 , 0.5 , 0.5 ), (0.5 , 0.5 , 0.5 )) ]) trainset = torchvision.datasets.CIFAR10( root=opt['train' ]['data_root' ], train=True , download=True , transform=transform ) testset = torchvision.datasets.CIFAR10( root=opt['test' ]['data_root' ], train=False , download=True , transform=transform )
该程序可以从配置文件中读取train -> dataroot的路径,并将数据集下载到这个位置。transform的作用是对图像数据进行预处理(这里是转化为张量并对图像张量进行标准化)。
模型结构
如果你希望保持该项目良好的延展性,未来开发了其他图像分类模型时可以方便地插入该工作区,可以先新建modules目录,并在其中新建文件__init__.py作为该工作区下的一个库。然后再在该目录中新建文件attention_cnn.py,在该文件中编写模型。
导入必要的库并实现注意力层的结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import torchimport torch.nn as nnimport torch.utilsclass SelfAttn (nn.Module): def __init__ (self, in_dim ): super (SelfAttn, self ).__init__() self .query = nn.Conv2d(in_dim, in_dim // 8 , kernel_size=1 ) self .key = nn.Conv2d(in_dim, in_dim // 8 , kernel_size=1 ) self .value = nn.Conv2d(in_dim, in_dim, kernel_size=1 ) self .softmax = nn.Softmax(dim=-1 ) def forward (self, x: torch.Tensor ): B, C, H, W = x.size() Q = self .query(x).view(B, -1 , H*W).permute(0 , 2 , 1 ) K = self .key(x).view(B, -1 , H*W) V = self .value(x).view(B, -1 , H*W) attention = self .softmax(torch.bmm(Q, K)) out = torch.bmm(V, attention.permute(0 , 2 , 1 )) out = out.view(B, C, H, W) return out + x
query:1*1卷积层,可以将输入特征映射到一个低维空间(C//8),减少了计算量key:1*1卷积层,用于计算注意力分数value:1*1卷积层,将输入特征映射到新的特征空间该层的前向传播forward函数用于计算输入图像x的自注意力分数矩阵,out诠释了特征图不同位置之间的相关性。残差连接(out + x)使得模型既可以学习注意力特征,又可以保留CNN提取的局部信息,避免信息的丢失。
接着实现包含该注意力层的CNN结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class AttentionCNN (nn.Module): def __init__ (self, num_classes=10 ): super (AttentionCNN, self ).__init__() self .conv1 = nn.Conv2d(3 , 64 , kernel_size=3 , padding=1 ) self .attn1 = SelfAttn(64 ) self .conv2 = nn.Conv2d(64 , 128 , kernel_size=3 , padding=1 ) self .attn2 = SelfAttn(128 ) self .conv3 = nn.Conv2d(128 , 256 , kernel_size=3 , padding=1 ) self .attn3 = SelfAttn(256 ) self .pool = nn.AdaptiveAvgPool2d((1 , 1 )) self .fc = nn.Linear(256 , num_classes) self .activate = torch.relu def forward (self, x ): x = self .activate(self .conv1(x)) x = self .attn1(x) x = self .activate(self .conv2(x)) x = self .attn2(x) x = self .activate(self .conv3(x)) x = self .attn3(x) x = self .pool(x).view(x.shape[0 ], -1 ) return self .fc(x)
在这个模块中,图像经过了三个【卷积+注意力】层,通道数不断增加(3
-> 64 ->
128),每个自注意力层计算图像各部分之间的注意力。池化层self.pool = nn.AdapterAvgPool2d将特征图压缩为(B, 256, 1, 1)的特征向量,并由fc全连接层将该向量映射到num_classes维度(这里为10),作为分类结果。
(神经网络可视化绘图工具:Netron )
模型训练
新建train.py,先导入必要的库和配置文件中的参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import torchimport torch.nn as nnimport torch.utilsimport torch.utils.datafrom torch.utils.data import DataLoaderfrom modules.attention_cnn import AttentionCNNfrom dataset import trainsetfrom tqdm import tqdmfrom time import timeimport osimport yamlfrom datetime import datetimenow = datetime.now() curr_time = now.strftime("%Y%m%d-%H%M%S" ) from tensorboardX import SummaryWriterwriter = SummaryWriter(log_dir=f'logs/tb_logger/{curr_time} ' ) with open ('options.yml' , 'r' ) as f: opt = yaml.safe_load(f) opt = opt['train' ] EPOCHS = opt['n_epochs' ] BATCH_SIZE = opt['batch_size' ] LR = opt['lr' ] SAVE_ROOT = opt['save_dir' ] os.makedirs(os.path.join(SAVE_ROOT, curr_time))
编写训练过程的主函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def train (model: AttentionCNN, trainloader: DataLoader, epochs, device ): model.train() global step_num for epoch in range (epochs): tic = time() total_loss, correct, total_samples = 0 , 0 , 0 for images, labels in tqdm(trainloader, ncols=60 ): images, labels = images.to(device), labels.to(device) optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() total_loss += loss.item() correct += (outputs.argmax(1 )==labels).sum ().item() total_samples += labels.size(0 ) writer.add_scalar('loss/steps' , loss.item(), step_num) step_num += 1 toc = time() train_acc = correct / total_samples print (f'Epoch {epoch+1 } /{epochs} Loss: {total_loss / len (trainloader): .4 f} Acc: {train_acc * 100 : .2 f} % (cost {toc-tic: .1 f} s)' ) writer.add_scalar('loss/epochs' , total_loss / len (trainloader), epoch + 1 ) writer.add_scalar('acc/train' , train_acc, epoch + 1 ) torch.save(model.state_dict(), os.path.join(SAVE_ROOT, curr_time, f'epoch_{epoch+1 } .pth' ))
在这里,criterion定义了模型使用的损失函数,optimizer是模型使用的优化器,决定了模型中参数的优化方式(如梯度下降、SGD等)。
flowchart BT
subgraph inputs
img[images]
l[labels]
end
subgraph model
optim[optimizer]
subgraph net[networks]
param[parameters]
end
end
out[outputs]
cr[criterion]
loss[loss]
result[[final results]]
img --> net --> out
out --> epoch{epoch <= MAX_EPOCHS?}
epoch -->|Yes| cr
epoch -->|No| result
l --> cr --> loss -->|"loss.backward()"| optim
optim -->|"optimizer.zero_grad()
optimizer.step()"| param
添加以下部分之后就可以尝试运行了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if __name__ == '__main__' : device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True ) model = AttentionCNN(num_classes=10 ).to(device) if opt['resume' ]: if os.path.exists(opt['pretrained_path' ]): model.load_state_dict(torch.load(opt['pretrained_path' ])) else : pass criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=LR) main(model=model, trainloader=trainloader, epochs=EPOCHS, device=device)
这个程序使用了tensorboard进行数据的可视化,我们可以方便地观察训练过程中模型准确率和损失的变化情况。以后有时间的话打算写一期如何使用tensorboard,先挖个坑在这
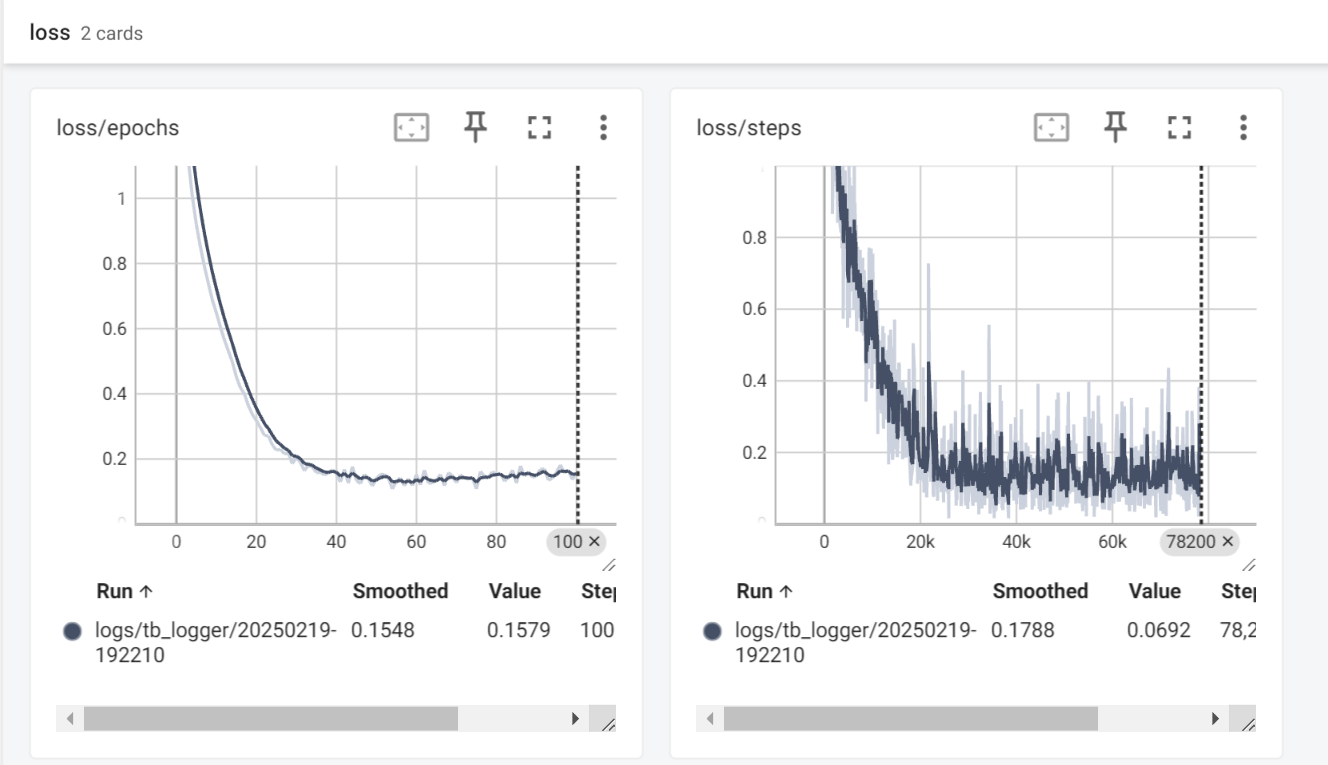
模型在100个训练周期内的损失变化情况 模型在100个训练周期内的损失变化情况
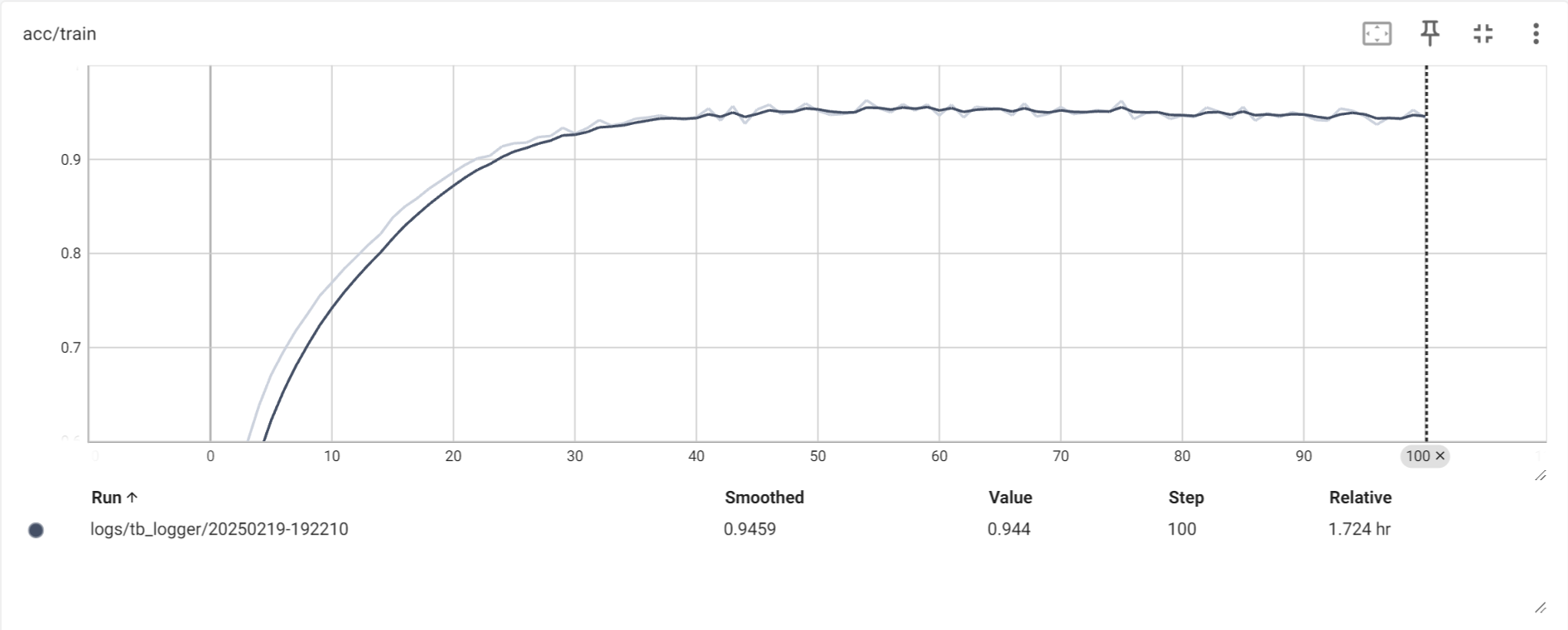
模型在100个训练周期内的准确率变化情况(在训练集上) 模型在100个训练周期内的准确率变化情况(在训练集上)
从图上可以看出,模型的准确率和损失在训练过程中的变化还是相对平稳的,并且最后在训练集上的准确率基本稳定在了95%左右。
为了考察模型的泛化能力,接下来还要对模型进行测试。
模型测试
在先前的配置文件options.yml中,添加以下内容:
1 2 3 4 test: data_root: './data' batch_size: 64 load_path: '/path/to/your/pretrained/weight'
新建文件test.py,模型测试程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import torchfrom torch.utils.data import DataLoaderfrom modules.attention_cnn import AttentionCNNfrom dataset import testsetimport osimport yamlwith open ('options.yml' , 'r' ) as f: opt = yaml.safe_load(f) opt = opt['test' ] BATCH_SIZE = opt['batch_size' ] LOAD_PATH = opt['load_path' ] def main (model: AttentionCNN, testloader: DataLoader, device ): model.eval () correct = 0 with torch.no_grad(): for images, labels in testloader: images, labels = images.to(device), labels.to(device) outputs = model(images) correct += (outputs.argmax(1 )==labels).sum ().item() acc = correct / len (testset) print (f'Acc: {acc: .4 f} ' ) return acc if __name__ == '__main__' : device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=True ) model = AttentionCNN(num_classes=10 ).to(device) assert os.path.exists(LOAD_PATH), 'Invalid load path.' model.load_state_dict(torch.load(LOAD_PATH)) main(model=model, testloader=testloader, device=device)
这样,在配置文件中设置一个存放模型权重的路径,程序就可以在控制台输出模型在测试集上的准确率了。由于我们先前的训练程序将模型在每个周期上的权重都保存了下来,我们对程序稍作修改就可以在tensorboard上输出模型在测试集上的准确率随训练周期的变化情况。(这部分改动我就不写了,感兴趣的读者可以自己尝试实现一下。从训练程序中应该可以看出来tensorboard的使用并不难)
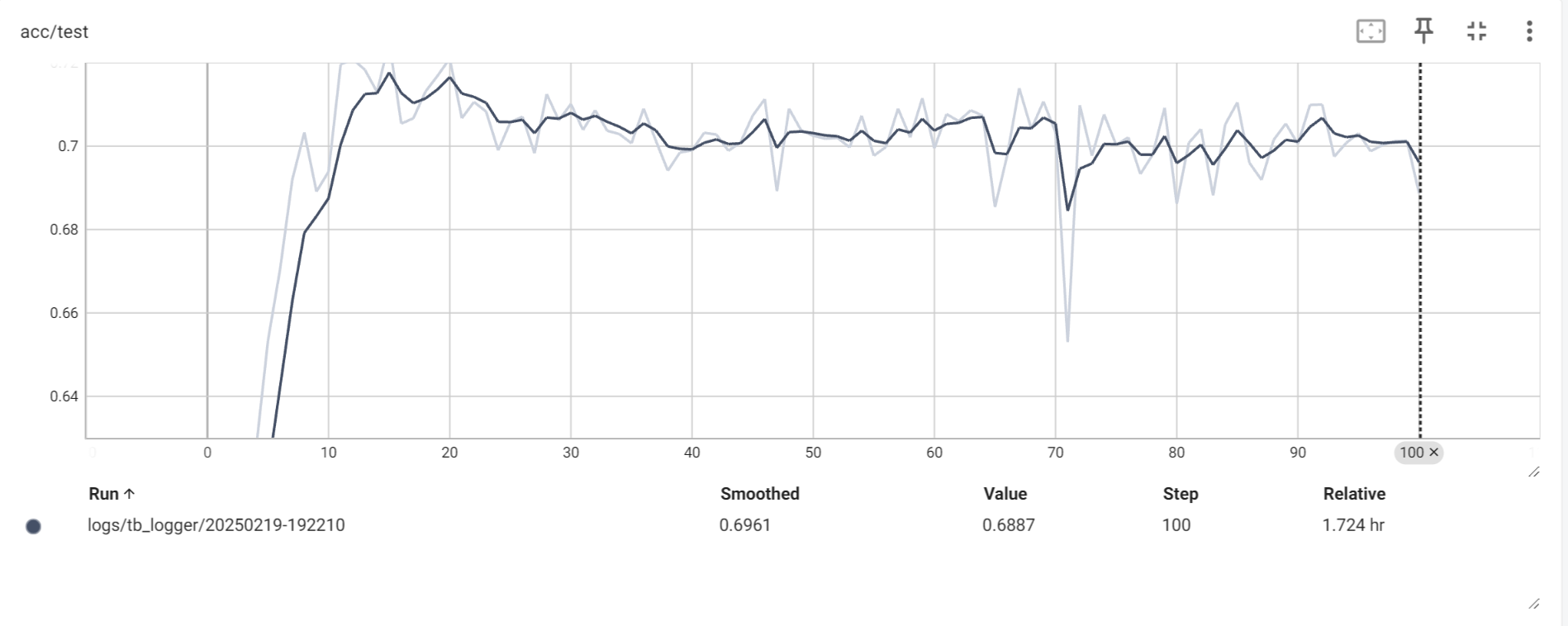
模型在100个训练周期内的准确率变化情况(在测试集上) 模型在100个训练周期内的准确率变化情况(在测试集上)
模型在测试集上的表现似乎只能用差强人意来形容。模型在第20个训练周期左右时准确率已经达到最高水平(72%左右),之后略微出现下降,最后在70%附近振荡,在其中一处甚至出现了严重的退化(Epoch
71, Acc
0.6530)。可见,模型在训练了20个周期之后就出现了过拟合 的现象。
在实际的模型训练任务中,需要将数据集划分为训练集、验证集和测试集,并在每个训练周期结束时使用验证集监测模型的泛化能力变化情况。这有助于我们监测模型是否发生过拟合等情况,并作出相应的调整。本文的模型并未引入验证流程。
但需要注意的是,测试集是不可以当作验证集使用的。 规范的训练流程中,模型面对测试集如同高三考生面对高考,是只能见一次的。根据模型在测试集上的表现而有针对地改变训练策略,实际上是一种作弊。但事实上很多论文为了刷指标都这么搞……懂得都懂
结语
在入门深度学习的过程中,如果想复现其他人的小项目的话建议把代码跟着手敲一遍,在敲的过程中可能会遇到很多不理解的问题,但起码不会漏掉很多问题,毕竟总有一条它们还是会再找上来,并且在需要独立实现项目的情况下变得更加棘手。(也算是个人的一点点小体会,我也是努力入门中T^T)