正则表达式介绍

什么是正则表达式?
学过编程的应该都知道正则表达式(regular expressions)这个东西,使用它可以方便地从文本中筛选出所需格式的字符串。
举个例子,很多网站的注册界面都会要求用户输入邮箱,那么如何判定用户输入的字符串是合法的邮箱格式呢?可以使用如下的正则表达式进行判定:
1 | ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ |
看起来还是很抽象的,但实际上把正则表达式中常用的语法搞清楚之后就一目了然了。
推荐一个用于测试和练习正则表达式的网站:https://regex101.com/
语法
正则表达式主要依赖于元字符。这些元字符往往具有特殊的含义,组成了正则表达式的语义和筛选条件。下面对一些主要的元字符作介绍:
| 元字符 | 描述 |
|---|---|
. |
匹配除换行符外的任意单个字符 |
[] |
可理解为一个字符集合,匹配方括号内的任意字符 |
[^ ] |
否定的字符种类,匹配除了方括号里的任意字符 |
* |
匹配不小于0个重复的在*号之前的字符 |
+ |
匹配大于0个重复的在+号之前的字符 |
? |
标记在?号前的字符为可选字符 |
{} |
通常作为量词使用,常用于限定一个或一组字符可以重复出现的次数 |
(xyz) |
字符集,匹配与括号内相等的字符串 |
\| |
或运算符,匹配该符号前或后的字符 |
\ |
转义字符,用于匹配保留的元字符 |
^ |
从开始行开始匹配 |
$ |
从末端开始匹配 |
基本匹配
这是一种最简单的正则表达式,由一些字母和数字组合而成,匹配其本身组成的字符串。例如,the匹配字符串the。
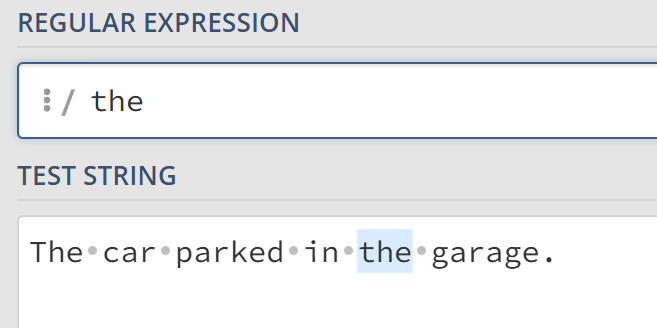
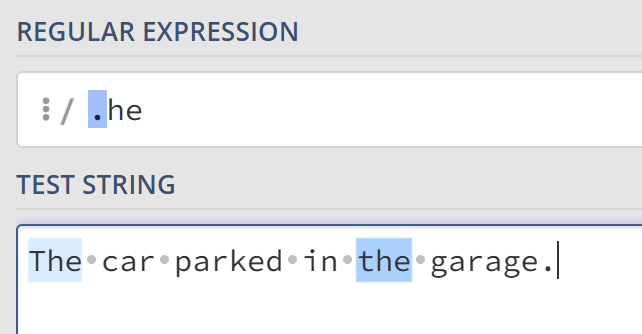
点运算符 .
最简单的元字符,可以匹配除换行符外的任意单个字符。例如对于正则表达式.he,它匹配任意一个字符后跟着he的字符串。
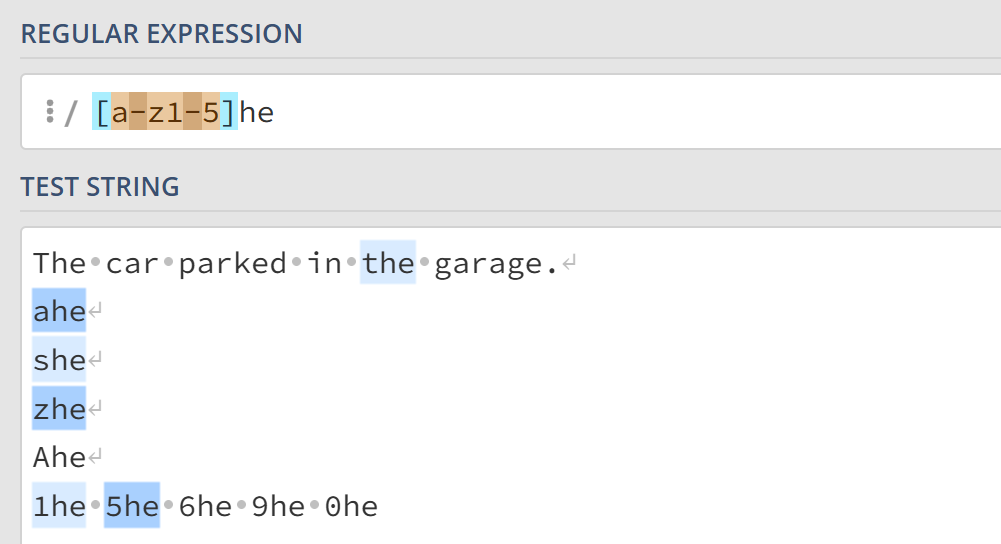
字符集 []
方括号用于指定一个字符集合,在方括号中使用连字符-指定字符集的范围。方括号内的字符集不关心顺序,类似于集合中元素的无序性。
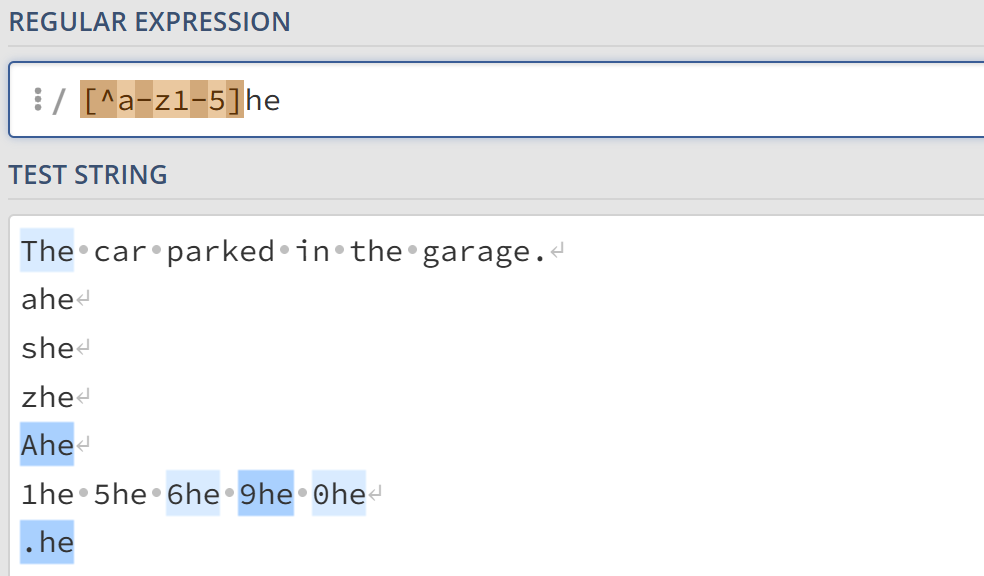
否定字符集 ^
一般使用^表示一个字符串的开头,但用在字符集中的开头时,它表示该字符集是否定的,匹配该字符集在所有字符的集合中的补集。
星号 *
星号匹配在它之前的字符出现不小于0次的字符。例如,[a-z]*表示所有小写字母组成的子串。
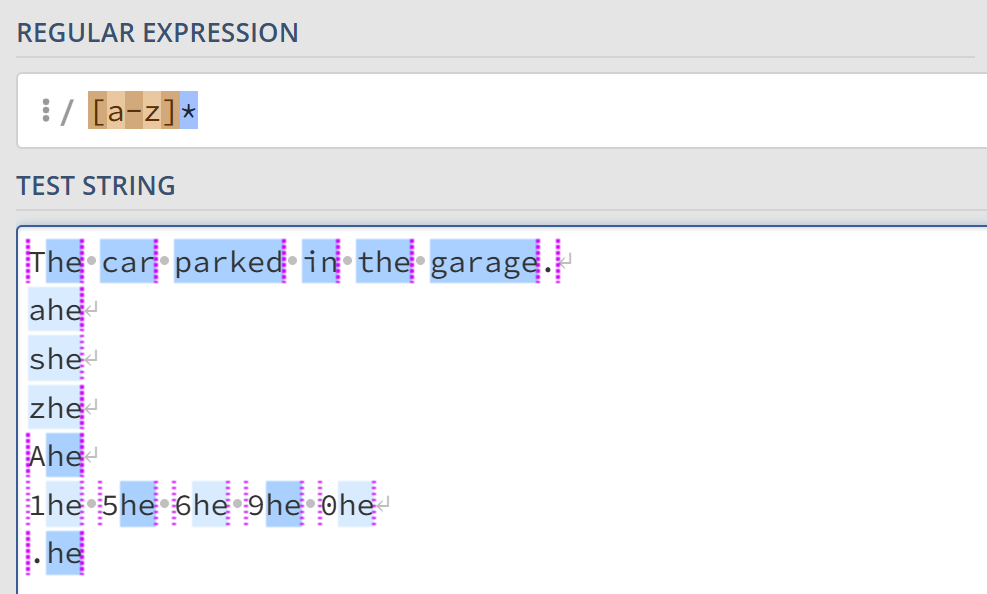
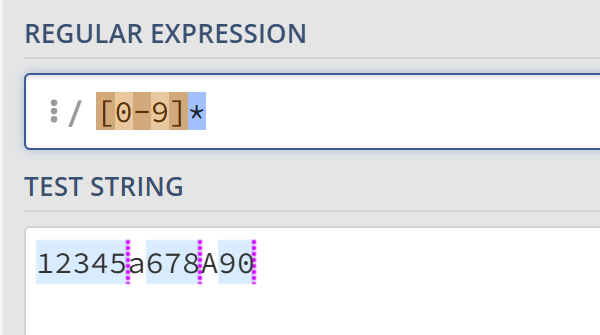
.和*搭配可以匹配所有的字符(.*)
加号 +
加号匹配在它之前的字符出现不小于1次的字符。例如a.+\s匹配以a开头、后面至少跟着一个字符并最终以空格结尾的子串。
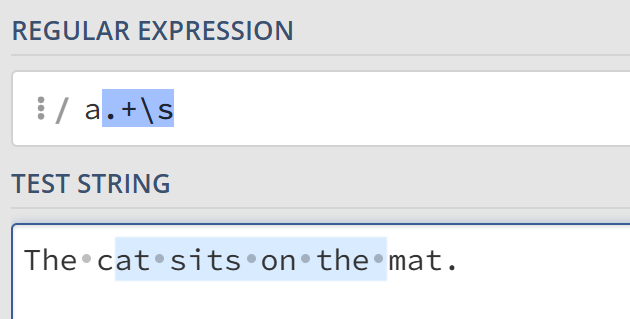
问号 ?
在?号前面的字符为可选,即出现0或1次。例如t?he匹配字符串the或he。
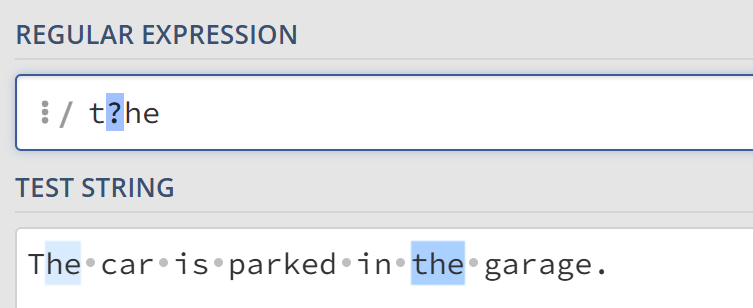
花括号 {}
花括号在正则表达式中常用作量词,限定其前面的字符可以重复出现的次数,可以传入不多于两个的参数。
例如a{2,5}匹配连续出现次数在2和5之间的连续a串,a{2,}匹配连续出现次数不小于2的连续a串,a{,5}匹配连续出现次数不多于5的a串。
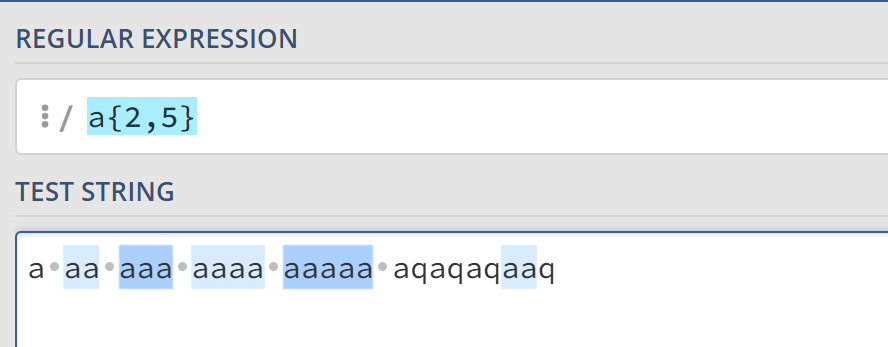
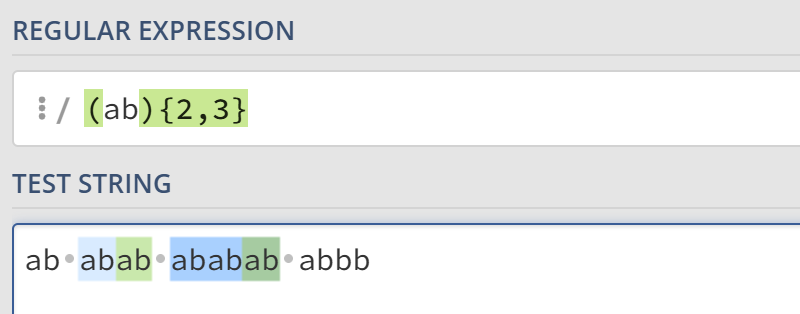
特征标群 ()
特征标群是一组写在小括号内的子模式,括号内的内容会被看作一个整体。例如ab*匹配a后连续出现不小于0个b的字符串,而(ab)*匹配连续出现不小于0个ab的字符串。
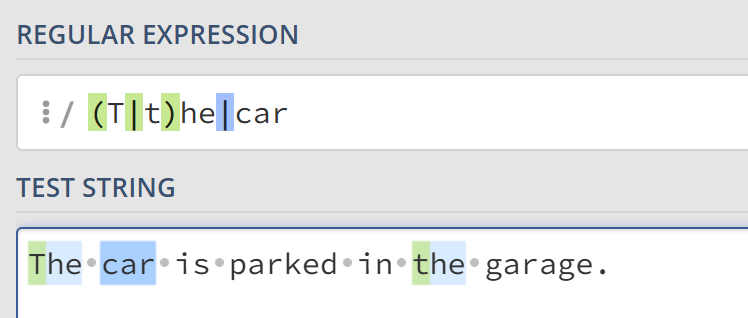
或运算符 |
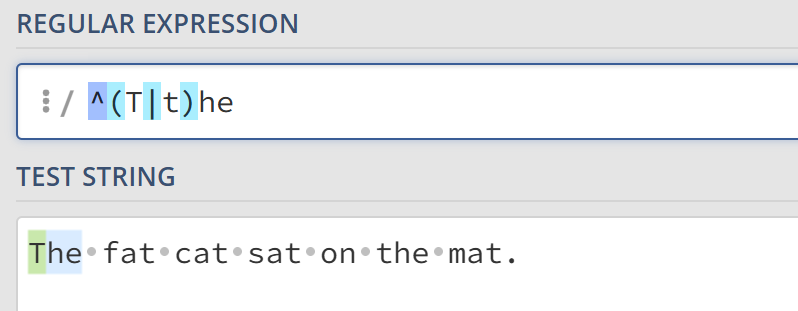
或运算符|表示“或”的判断条件。如(T|t)he|car匹配The,the和car。
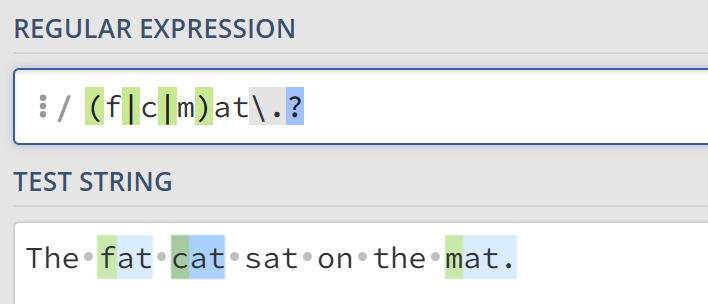
转义字符 \
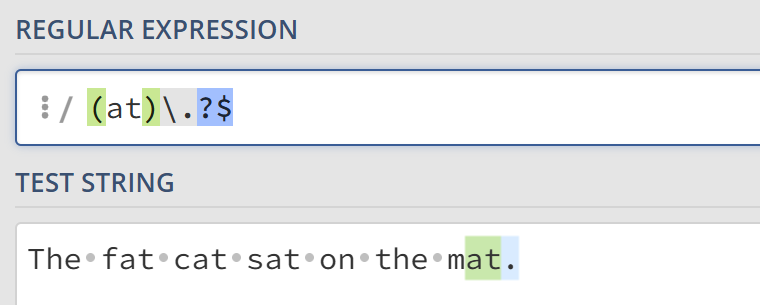
转义字符用于转码紧跟其后的特殊字符,例如以上提到的这些。如果想要在字符串中匹配这些字符需要在其前面加上\符号。例如\.用于匹配字符.。值得注意的是,如果再在后面添加问号,即\.?,表示该字符(.)是选择性匹配的。
锚点 ^与$
锚点^和$分别表示输入的字符串的开头和结尾。例如,^(T|t)he仅匹配在句首出现的the或The,而(at)\.?$仅匹配在句尾出现的at.或at。
简写字符集
正则表达式提供了一些常用的字符集简写:
| 简写 | 描述 |
|---|---|
\w |
匹配所有字母和数字,相当于[a-zA-Z0-9_] |
\W |
匹配所有非字母数字,相当于[^\w] |
\d |
匹配数字,相当于[0-9] |
\D |
匹配非数字,相当于[^\d] |
\s |
匹配空格字符 |
\S |
匹配非空格字符 |
\f |
匹配一个换页符 |
\n |
匹配一个换行符 |
\r |
匹配一个回车符 |
\t |
匹配一个制表符 |
\v |
匹配一个垂直制表符 |
\p |
匹配CR/LF(相当于\r\n),用于匹配DOS行终止符 |
零宽度断言
包括先行断言和后发断言,匹配结果不包含该确定格式,仅作为约束条件。共包括四类:
| 符号 | 描述 |
|---|---|
?= |
正先行断言 |
?! |
负先行断言 |
?<= |
正后发断言 |
?<! |
负后发断言 |
看名称可能有点难理解,通俗点解释就是: - “正/负”表示该断言用于判断存在某格式(正)还是排除某格式(负); - “先行/后发”表示该断言用于筛选其后跟随某格式(先行)还是其前跟随某格式(后发)。
下面作出更详细的解释:
- 先行断言用于根据第一部分表达式之后是否存在断言定义的表达式进行筛选。
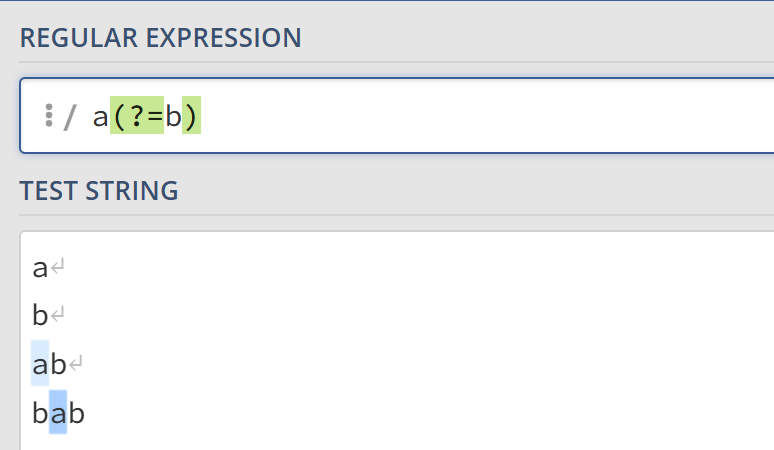
- 正先行断言表示第一部分表达式之后必须跟着
?=定义的表达式。比如,a(?=b)匹配后面跟着b的a。如果a后面没有b则不会被匹配。被断言定义的表达式b不会被匹配。
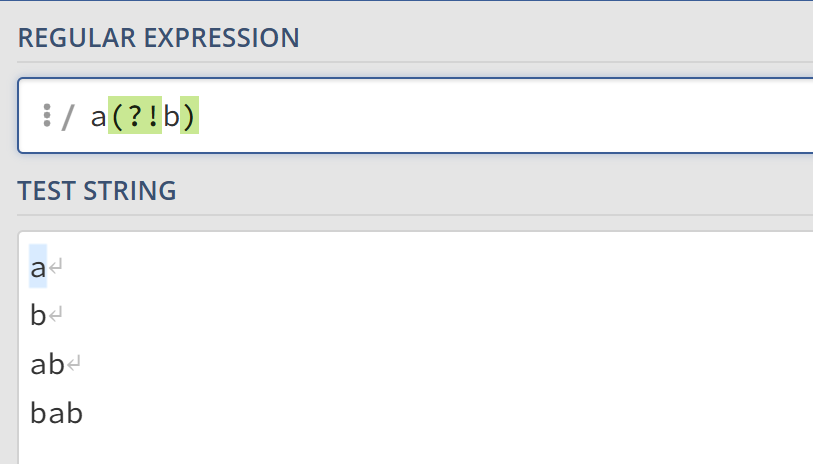
- 负先行断言
?!则相反,简单理解为正先行断言的反例即可。
- 正先行断言表示第一部分表达式之后必须跟着
- 后发断言用于根据第二部分表达式之前是否存在断言定义的表达式进行筛选。
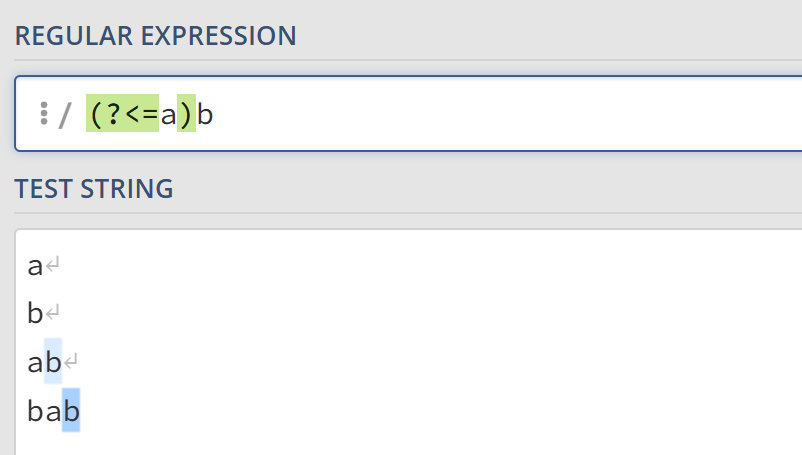
- 正后发断言表示第二部分表达式之前必须跟着
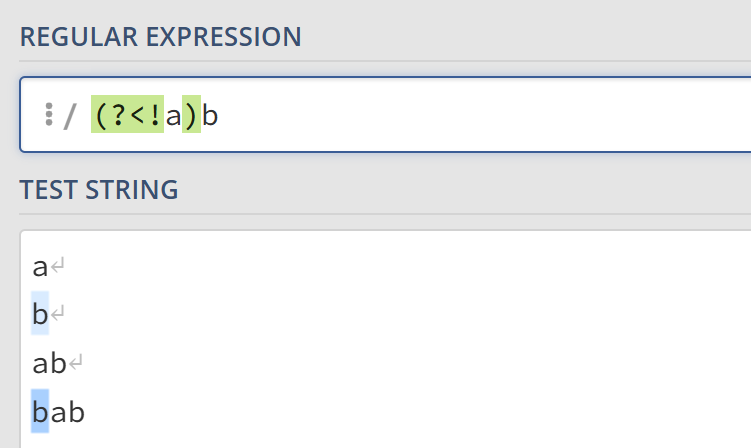
?<=定义的表达式。比如(?<=a)b匹配前面有a的b。如果b前面没有a则不会被匹配。被断言定义的表达式a不会被匹配。 - 负后发断言
?<!则相反,简单理解为正后发断言的反例即可。
- 正后发断言表示第二部分表达式之前必须跟着
模式修正符
模式修正符也叫标志,可以用于修改表达式的搜索结果。这些标志可以任意组合使用,属于整个正则表达式的一部分。这里仅介绍三个最常用的模式修正符。
| 标志 | 描述 |
|---|---|
g |
全局搜索 |
i |
忽略大小写 |
m |
多行修饰符:锚点元字符^和$工作范围在每行的起始 |
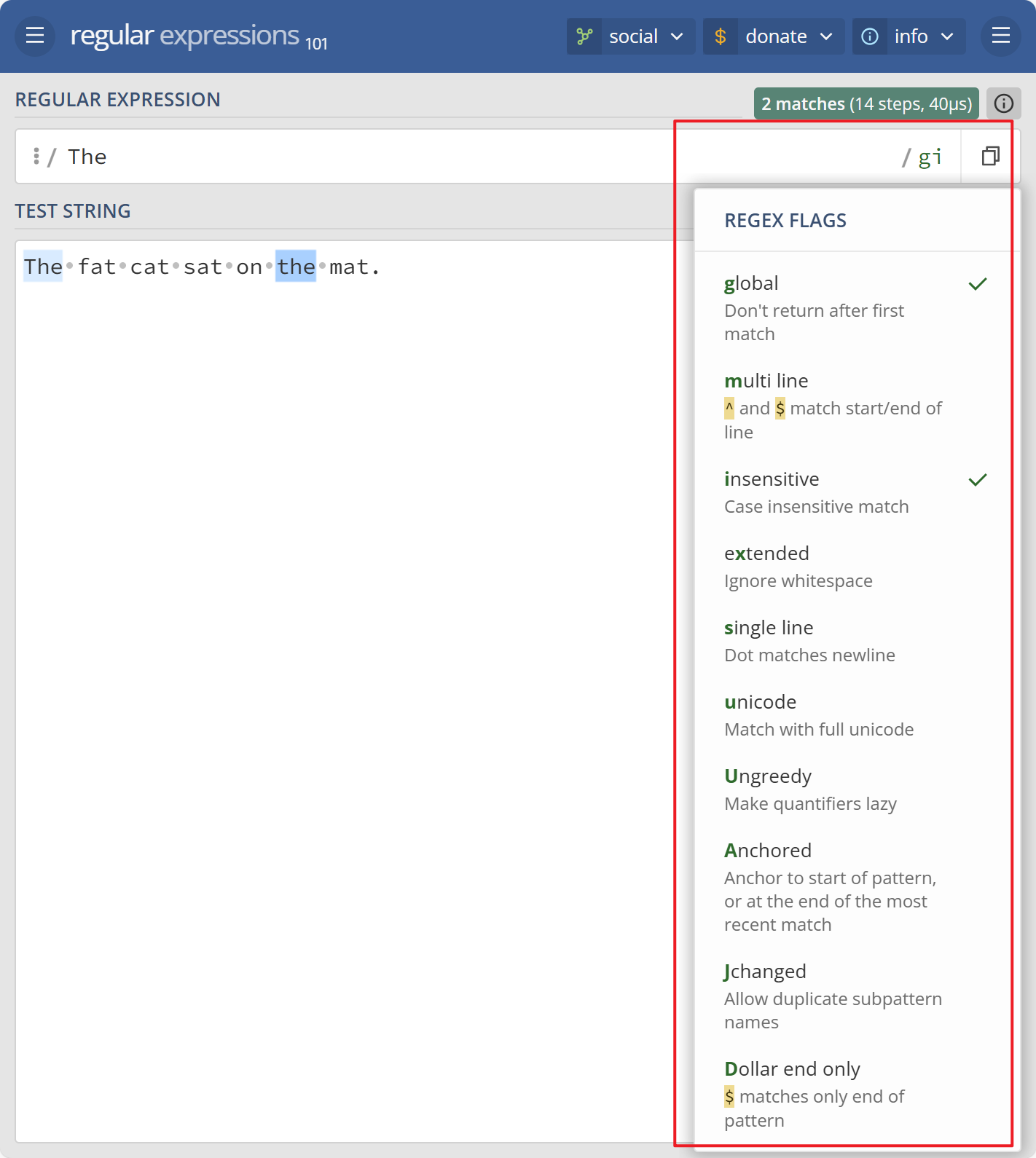
全局搜索
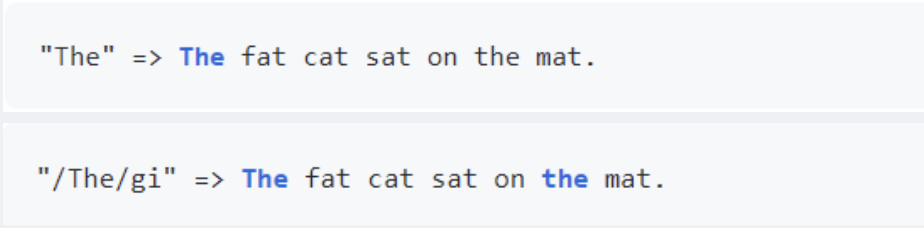
g常用于执行一个全局的搜索匹配,即不仅仅返回第一个匹配的,而是返回全部的匹配结果。忽略大小写标志
i顾名思义,不再赘述。多行修饰符
m可以使得锚点元字符^和$在输入字符串的每行的开头和结尾均生效。
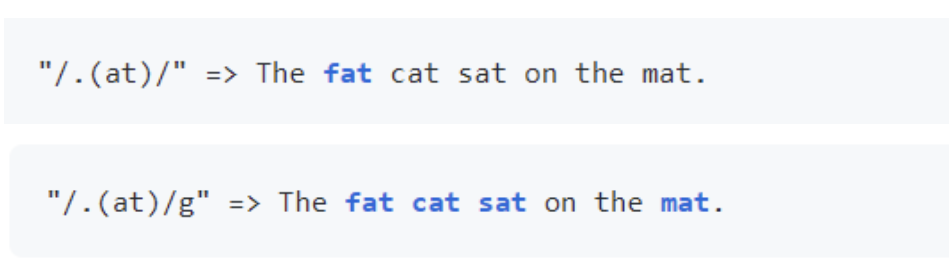

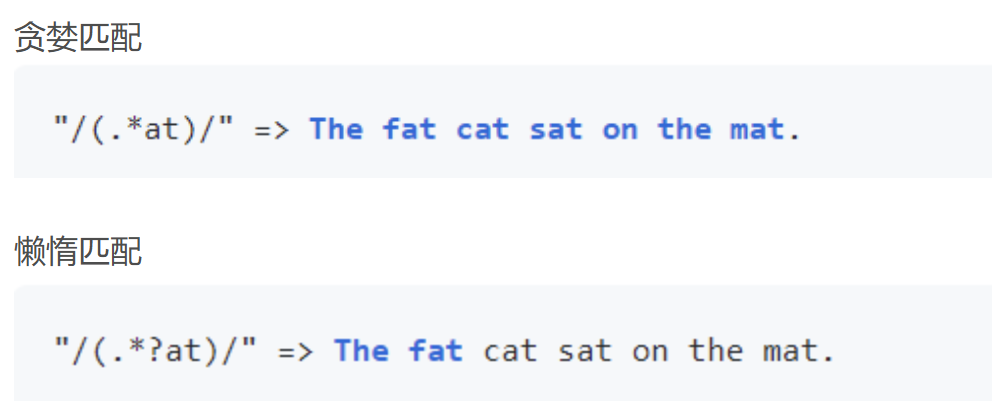
贪婪匹配与惰性匹配
正则表达式默认采用贪婪匹配模式,在该模式下意味着会匹配尽可能长的子串。我们可以使用?将贪婪匹配模式转化为<b<惰性匹配模式,该模式下会匹配尽可能短的子串。
- Title: 正则表达式介绍
- Author: Jachin Zhang
- Created at : 2025-02-24 22:17:52
- Updated at : 2025-02-28 23:03:55
- Link: https://jachinzhang1.github.io/2025/02/24/regular-expressions/
- License: This work is licensed under CC BY-NC-SA 4.0.