深度学习基础:基于DDPM模型的生成模型demo笔记(一)

引言
扩散模型是如今计算机视觉领域的热门话题,很多任务(如图像生成、图像修复等)都是基于该模型进行研发。在该算法中,最关键的部分是需要得到反向去噪过程中每一步去掉的噪声\(\epsilon_\theta(\mathbf{x}_t,t)\)。由于这部分噪声几乎无法直接通过公式计算得到,我们需要使用神经网络拟合。目前的主流方法是使用含残差操作的UNet,实验效果明显好于CNN。
该demo将基于DDPM模型和UNet构建一个生成模型,目标是通过在数据集上训练以使该模型可以生成相应数据集风格的图片(举个例子,我们可以让这个模型在MNIST数据集上训练,生成手写数字的灰度图像)。更进一步地,我们将尝试在训练过程中加入标签特征的嵌入,使其可以实现条件生成(比如我传入一个标签参数0,模型可以生成手写数字0的图像)。
该项目中我们使用MNIST和CIFAR-10这两个数据集上进行训练。
项目参考
本项目主要参考了这篇博客:《扩散模型(Diffusion Model)详解:直观理解、数学原理、PyTorch 实现》,并在此基础上进行改进。
关于该模型的算法原理就不在这篇博客做过多赘述了,可以移步至我的博客《学习笔记:扩散模型算法介绍》或上面项目参考中提到的博客。这里主要记录我的项目构建历程。
项目构建
由于该项目有些小细节被重构过(如部分函数的用法和参数等),因此不能保证该代码直接全部复制下来之后就能跑,可能会有些报错。但整体的框架是不变的,若遇到相关错误烦请读者自行排查,应该不会很多,也不会影响对该项目的理解。
数据集
为了方便参数的调整,我们还是先建立一个配置文件用于存储各项参数信息。新建options.yml,添加设备和数据集的信息:
1 | device: 'cuda:0' |
新建dataset.py,代码如下:
1 | import torchvision |
这部分代码应该很简单,不必多说。目前配置文件在数据集的选择上只支持MNIST和CIFAR-10数据集,之后应该会做相应的扩展。
DDPM模型
接下来我们通过创建DDPM类实现相关运算。在options.yml中添加以下内容:
1 | ddpm: |
图像的扩散过程包含n_steps步,公式里每一步的beta值可以使用torch.linspace(min_beta, max_beta)线性地生成一个序列,每个时间步使用对应的beta。接着可以根据公式
\[
\alpha_t=1-\beta_t, \bar{\alpha}_t=\prod_{i=1}^t{\alpha_i}
\] 计算每个时刻的alpha和alpha_bar。
新建ddpm.py,创建DDPM类:
1 | import torch |
正向过程方法可以根据公式计算正向过程中的x_t(即逐渐被噪声覆盖的过程中的图像)
1 | def sample_forward(self, x, t, eps=None): |
接着实现反向过程,该过程中DDPM会使用神经网络预测每一轮去噪的均值,把x_t逐步复原回x_0以完成图像生成。
1 | def sample_backward(self, img_shape, net, device, simple_var=True): |
UNet构建
本部分可以分为三个子部分:用于对时间进行时间步编码的PositionalEncoding类、UNet网络的组成部分UNetBlock类和网络主干UNet类。
在配置文件中加入以下内容:
1 | network: |
新建networks.py,导入必要的库:
1 | import torch |
我们首先实现负责时间步编码的PositionalEncoding类。
在扩散模型中,时间步是一个比较重要的信息——它和图像每一步增加/去除的噪声具有很高的相关性。之所以我们不直接使用一个时间步索引的标量(如0, 1, 2...)告知模型当前的时间步,是因为这些数值缺乏结构,模型难以从其中学习到有效的时序关系。它有可能错误地学习到这些数值之间绝对的大小关系(比如模型会误以为时间步10比1重要,但实际上它们同样重要),而这不是我们期望看到的。换句话说,对时间步进行编码可以让时间也变成模型可从中学习的特征之一。
同时,对时间步进行编码操作可以为模型带来更丰富的信息,也增强了可扩展性——我们之后就可以尝试将标签的类别编码信息融入时间步编码,让模型实现条件生成。
一种非常常用的编码方式是位置编码,尤其是正弦-余弦编码。编码后的向量之间的欧氏距离仍然反映了它们之间的相对间隔,有助于让模型理解不同时间步t之间的关系,而不仅仅是谁比谁大。
1 | class PositionalEncoding(nn.Module): |
该类的初始化参数为: -
max_seq_len:位置编码的最大长度,即序列的最大长度。这里将设为DDPM的时序长度n_steps。
-
d_model:编码向量(嵌入)的维度,必须是偶数,因为正弦和余弦交替填充向量。
该类首先创建一个形状为(max_seq_len, d_model)的全零矩阵pe用于存储位置编码。i_seq用于生成位置索引pos表示序列中每个token的索引,j_seq用于生成偶数索引two_i用于计算d_model维度的分量。接下来计算时间步的位置编码,公式为:
\[
\begin{aligned}
PE_{\left( pos,2i \right)}&=\sin \left(
\frac{pos}{10000^{\frac{2i}{d_m}}} \right)\\
PE_{\left( pos,2i+1 \right)}&=\cos \left(
\frac{pos}{10000^{\frac{2i}{d_m}}} \right)\\
\end{aligned}
\]
偶数索引使用正弦编码,奇数索引使用余弦编码。将它们组合起来扩展到pe的维度形成完整的时间步编码。
接下来将pe的值作为Embedding层的参数,并禁止其梯度更新使其成为固定的位置编码。
接下来实现组成UNet的模块,UNetBlock类。
1 | class UNetBlock(nn.Module): |
这块没太多好说的,标准化 -> 卷积 -> 激活 -> 卷积 -> 与输入残差连接(可选) -> 激活 -> 输出。
下面是重头,实现预测噪声的模型核心,UNet类。
关于UNet的讲解和简要的代码实现可移步此博客《UNet结构介绍》。下面是将要实现的结构的示意图:
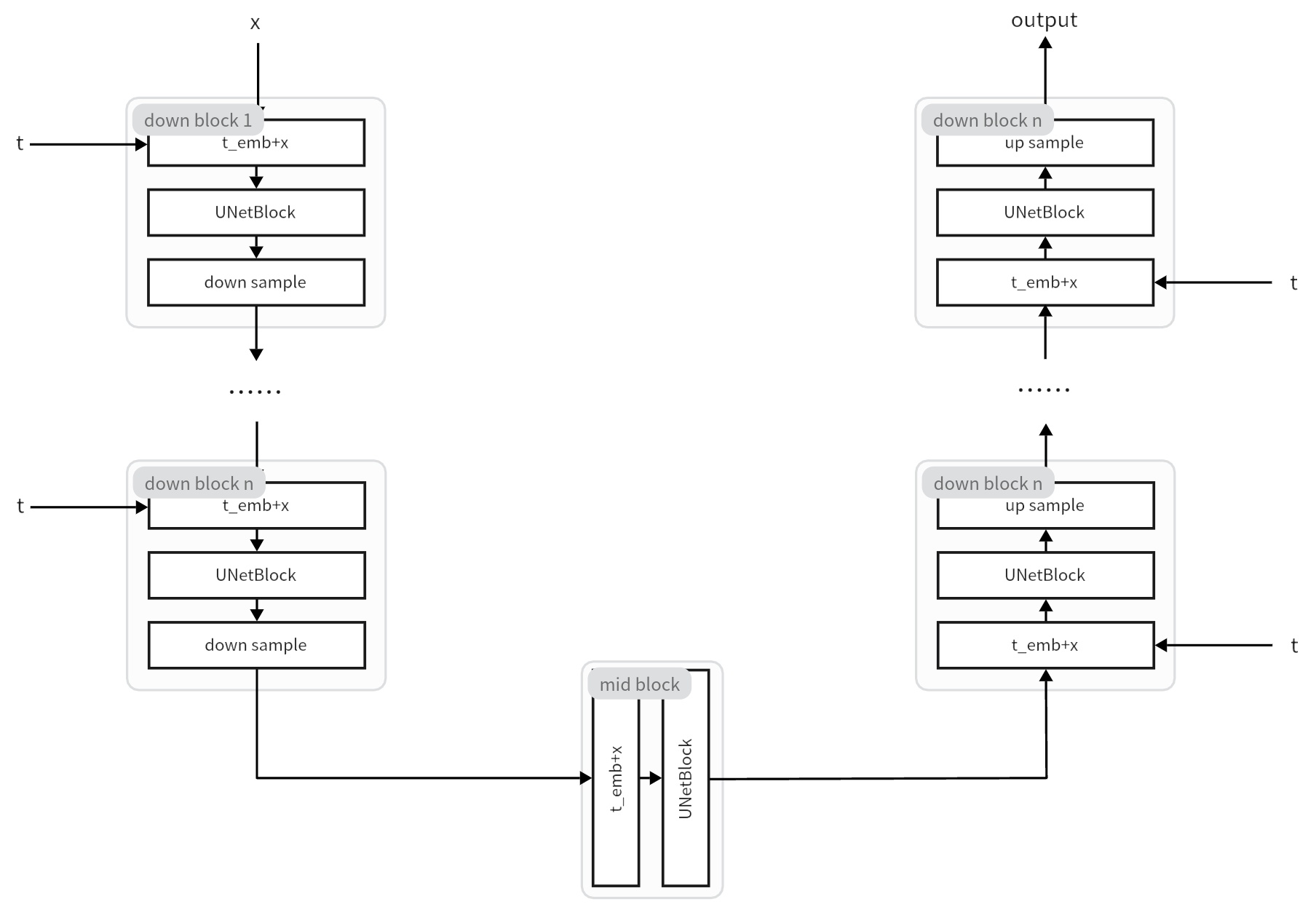
这里是代码实现:
1 | class UNet(nn.Module): |
我们可以写一个对外的初始化网络的函数:
1 | def build_network(n_steps: int, |
日志输出
为了更好地保存每次模型训练的信息便于后期查看、对比效果,我们要做好日志的输出与保存工作。python中自带logging库可以帮助我们完成相关工作。新建logger.py,加入以下内容:
1 | import logging |
关于logging模块的用法可以参考这篇博客:Python
logger模块 - 博客园
训练阶段
在配置文件加入训练部分的参数:
1 | train: |
先导入必要的包以及完成初始化工作:
1 | import torch |
训练部分的主函数平平无奇:
1 | def train(ddpm: DDPM, dataloader, net: nn.Module, device): |
程序的入口:
1 | if __name__ == '__main__': |
悲报。这部分在tensorboard上的实验数据被我不小心误删了(哭)就实验的情况而言,模型在MNIST数据集上的训练损失明显小于在CIFAR-10上的损失,前者的损失波动也显著地小于后者。
测试阶段
在配置文件加入测试部分的参数:
1 | test: |
其中n_samples参数是模型生成的一张大图里包含的小图——因为MNIST和CIFAR-10的图片都非常小,我们可以通过一些处理让若干小图组成一张大图,顺便看下模型生成效果的稳定性。
鉴于我们并没有所谓的测试标签用于衡量模型在测试集上表现的好坏,只好让它尝试生成一组数据来检验一下模型的训练效果。新建test.py,加入以下内容:
1 | import numpy as np |
结果展示与分析
模型分别在MNIST和CIFAR数据集上训练10个周期,并分别生成一组图像。先在用MNIST训练的模型上浅浅看下效果:

效果其实还算差强人意,只是模型有一定几率生成一些神秘数字(毕竟模型并不认识数字这个图案的含义,它只会生成类似风格的图案,反映在这上面就是一个黑底白字的符号),另外部分生成的数字字体也有点过于潦草。不过毕竟只训练了10个周期,还是有待优化的。
接下来将目光转向CIFAR-10队:

寄了。
看来这个模型的拟合能力还不能应付稍微复杂一些的多通道图像任务——因为这个模型并不只是生成了一些奇怪的物体,而是根本无法形成有意义的图案,整张图片只是一个发生偏移的色块。
下一步的优化方案:
加入标签信息,使模型可以实现标签生成;
强化模型的学习能力,力求让模型加强在CIFAR-10上的生成能力;
对模型进行一些其他的优化,比如加入自注意力机制等。
该系列未完待续!
- Title: 深度学习基础:基于DDPM模型的生成模型demo笔记(一)
- Author: Jachin Zhang
- Created at : 2025-03-05 22:00:27
- Updated at : 2025-03-06 21:39:50
- Link: https://jachinzhang1.github.io/2025/03/05/ddpm-project-1/
- License: This work is licensed under CC BY-NC-SA 4.0.